MoA BEATS GPT4o With Open-Source Models!! (With Code!)
Analyse des Modèles de Langage
Cette section initiale aborde la capacité des modèles à terminer les phrases avec le mot "Apple" et l'efficacité du modèle Quen.
Capacité des Modèles de Langage
- Les modèles ont du mal à terminer les phrases avec le mot "Apple".
- Le modèle Quen a réussi cette tâche, démontrant une performance impressionnante.
Mélange d'Agents : Une Approche Révolutionnaire
Présentation de la recherche récente sur le Mélange d'Agents (MOA) comme une avancée supérieure à GPT-3 dans le domaine de l'intelligence artificielle.
Avancée par rapport à GPT-3
- MOA surpasse GPT-3, leader actuel, en utilisant un ensemble d'agents travaillant ensemble.
- La recherche publiée met en avant le concept de "mixture of agents" pour améliorer les capacités des modèles LLM.
Intelligence Collective et Cadres Agentic
Discussion sur l'intelligence collective des modèles open-source et l'efficacité des cadres agentic dans la production de résultats optimaux.
Puissance des Cadres Agentic
- Les cadres agentic sont puissants lorsqu'ils permettent aux grands modèles linguistiques de collaborer.
- Lorsque des modèles spécialisés travaillent ensemble, ils peuvent rivaliser avec les modèles généralistes comme GPT-3 tout en étant plus efficaces et moins coûteux.
Approche MOA et Performances Améliorées
Explication approfondie du concept MOA et comment il exploite les forces collectives pour surpasser les normes actuelles.
Performance Supérieure
- MOA utilise plusieurs agents open-source pour obtenir un score élevé sur alpaca eval 2.0, dépassant largement GPT-3.
- La publication du code source offre une opportunité d'apprentissage pratique pour explorer cette approche novatrice.
Implémentation Réussie de MOA
Détails sur la mise en œuvre réussie de MOA qui dépasse significativement les performances antérieures telles que celles de GPT-3.
Réussite Technique
- L'utilisation combinée d'agents open-source dans MOA a permis d'obtenir un score remarquablement élevé.
- La mise à disposition du code source ouvre la voie à davantage d'applications pratiques et expérimentations.
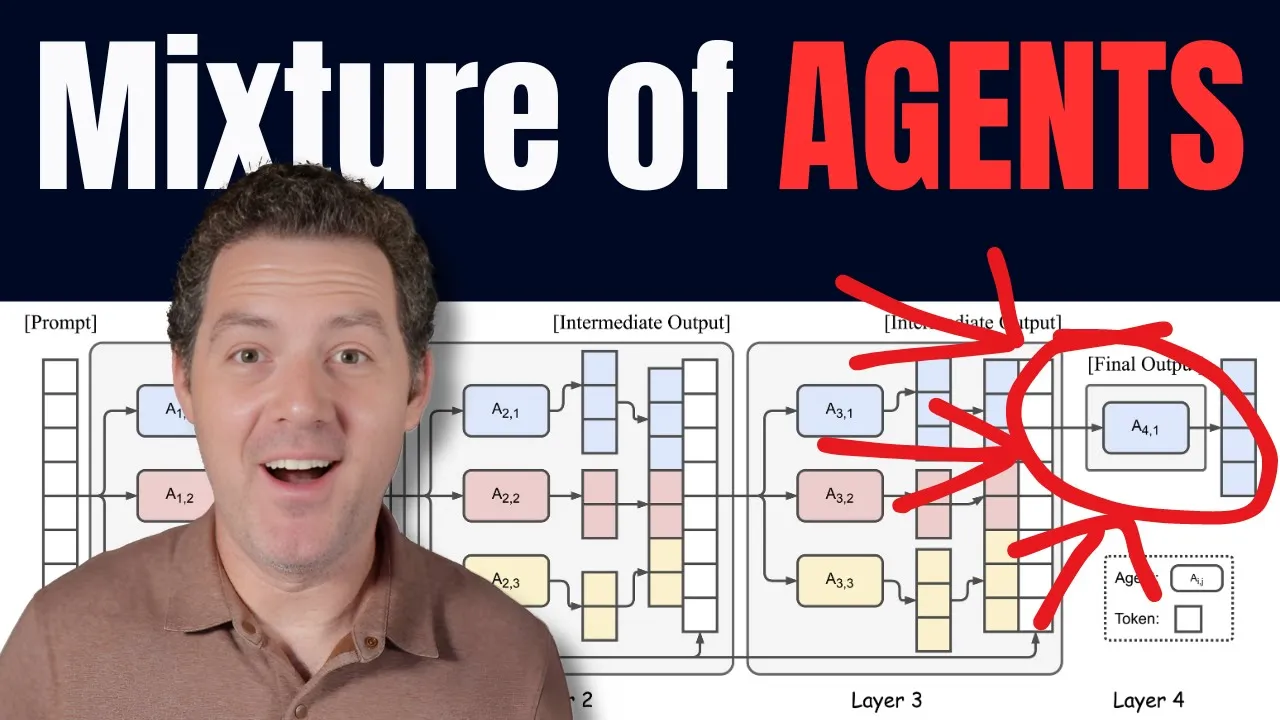
Architecture du Mélange d'Agents
Description détaillée de l'architecture complexe du Mélange d'Agents (MOA), mettant en lumière ses multiples couches et interactions entre agents.
Structure Complexes
- Le MOA est composé de trois couches distinctes, chacune contenant trois agents travaillant conjointement.
- Les agents peuvent partager le même modèle ou utiliser différents modèles à chaque couche, offrant ainsi une flexibilité intéressante dans le processus décisionnel.
Intégration Efficace des Capacités Diversifiées
Explique comment le MOA intègre efficacement diverses capacités et perspectives pour produire un modèle combiné robuste et polyvalent.
Intégration Harmonieuse
- Les agents utilisent les sorties des couches précédentes comme informations auxiliaires pour générer des réponses affinées.
Démo et Discussion sur l'Utilisation de Différents Modèles de Langage
Aperçu de la Section: Cette section met en avant l'utilisation de différents modèles de langage pour la synthèse sophistiquée des données, soulignant l'importance d'intégrer diverses perspectives pour améliorer les performances.
Analyse des Modèles de Langage
- L'agrégateur synthétise de manière sophistiquée au lieu de simplement sélectionner, montrant une performance croissante jusqu'à atteindre un plateau vers le quatrième niveau.
- Les expériences avec plusieurs proposants démontrent un avantage constant en termes de performances, soulignant que l'intégration d'une variété d'entrées provenant de différents modèles améliore significativement les résultats.
- Met en lumière la valeur d'utiliser des perspectives et capacités diverses offertes par différents modèles, comparant cela à la collaboration humaine où la magie émerge lorsque des individus aux opinions variées travaillent ensemble.
Test et Résultats
- Utilisation des modèles LLMS comme référence pour le test, soulignant l'utilisation des modèles Quen 272b, Quen 1.5 72b, Mixol 8X 22 et DBRX Instruct via Together AI.
- Malgré quelques erreurs liées aux limites d'utilisation, les tests ont été concluants montrant une gestion efficace des erreurs et une performance satisfaisante dans la génération des réponses attendues.