The Battle of Polynomials | Towards Bayesian Regression
Welcome and Introduction
In this section, the speaker introduces the tutorial on building a statistical model based on a book by Doctor Bishop. The focus is on comparing different model variants and addressing challenges in modeling.
Building the Synthetic Data Set
- The synthetic data set is generated using a sine function with values between zero and one.
Understanding Input and Output Variables
- The X-axis represents the independent variable, while the Y-axis represents the target variable (T).
- Python code is used to generate a smooth plot of the data set with many data points.
Modeling Challenges and Solutions
This section delves into challenges faced during modeling, such as limited data sets and errors (noise), along with solutions like adding random noise to simulate errors.
Training Data Selection
- Only ten data points are selected for modeling, termed as training data.
- Errors in datasets used for modeling are referred to as noise.
Hypotheses in Modeling
- Initial hypothesis assumes a simple linear relationship between target and independent variables.
- Adding quadratic terms aims to capture the curviness of the underlying function.
Model Representation
This part discusses expanding model representation beyond linear functions by including higher-order terms like squares and cubes of independent variables.
Including Higher Order Terms
- Quadratic term addition aims to accommodate both linear and quadratic aspects of the dataset.
- Model can include terms of higher order than just squares of independent variables.
Linear Model Formulation
- A more general representation includes various order terms, termed as a linear model due to linearity with respect to weights.
- Mathematical conveniences accompany using a linear model despite its simplicity compared to physical phenomena.
New Section
In this section, the speaker discusses the formulation of a criterion to measure the difference between predicted and actual target variable values in a model.
Formulating a Criterion for Model Evaluation
- The speaker introduces the concept of using a sum squared error function as a criterion to evaluate model performance, emphasizing the importance of squaring differences to ensure all errors are positive.
- Reasons for squaring differences include highlighting larger discrepancies and simplifying derivative calculus, essential for finding optimal weights that minimize total error.
- The sum squared error function is explained as aiding in identifying global minima through derivative calculus, crucial for determining optimal weight values in the model.
New Section
This section delves into the process of taking gradients and solving linear equations to obtain weights in a model.
Derivative Calculus and Weight Calculation
- The speaker illustrates taking gradients by representing the model function Y as a sum of weights and independent variables, emphasizing simplifications achieved through derivative calculations.
- By expanding Y and isolating terms, the speaker demonstrates how matrix representation aids in solving linear equations to obtain weights efficiently.
- The solution to linear equations is presented using matrix-vector products, showcasing how mathematical concepts seamlessly translate into Python implementation using numpy.
New Section
This section explores building models with varying polynomial degrees to understand their impact on capturing underlying functions.
Model Building with Polynomial Degrees
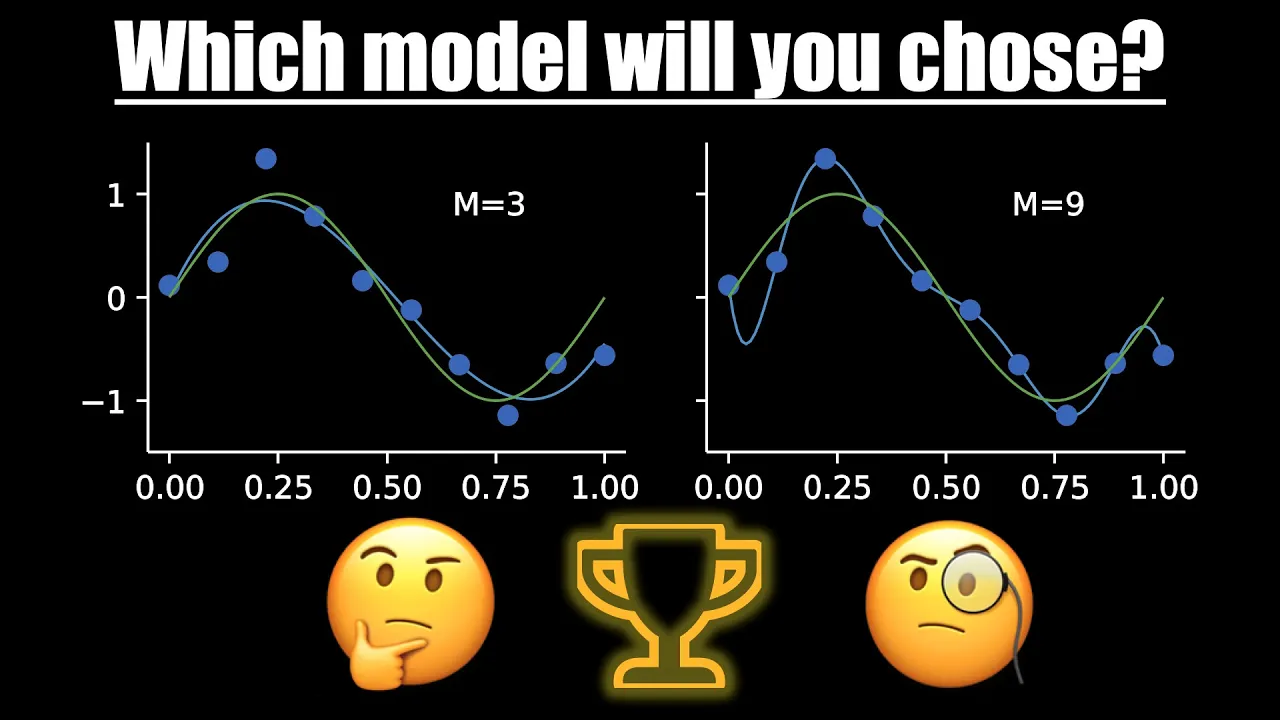
- Four models are constructed with different polynomial degrees: constant (degree 0), line (degree 1), cubic (degree 3), and ninth-degree polynomial. Each model's plot reflects its ability to capture underlying functions effectively.
New Section
In this section, the speaker discusses the selection of models based on polynomial degrees and the importance of choosing the right model for accurate predictions.
Selecting the Right Model
- The dilemma lies in choosing between a polynomial model of degree 9 that passes through all data points but doesn't resemble the true function, and a degree 3 model that captures a sine function despite missing some points.
- Decision-making criteria should extend beyond visual plots, especially in multivariate datasets where visualization may not suffice due to high dimensions.
- The ultimate goal of modeling is accurate predictions on new data points unseen by the model during training, emphasizing the need for testing with a separate dataset.
- Evaluating models using root mean squared error (RMSE) helps compare performance across different polynomial degrees, with lower RMSE indicating better models for test data prediction.
New Section
In this section, the speaker discusses the concept of regularization to combat overfitting in machine learning models.
Regularization Technique
- Regularization involves adding a term to the loss function to control weights.
- The amount of regularization is controlled by Lambda, a hyperparameter determined through experimentation.
- Ridge regression is a form of regression that incorporates regularization to adjust weights effectively.
New Section
This part delves into the impact of different Lambda values on model performance and visualization.
Effect of Lambda Values
- A Lambda value of zero indicates no regularization, resulting in unchanged model behavior.
- Excessive regularization with Lambda equaling one leads to poor model performance.
- Optimal results are achieved with an appropriate Lambda value, balancing regularization and model accuracy.
New Section
The discussion shifts towards evaluating model performance using root mean squared error and the implications of regularization.
Model Evaluation and Impact
- Regularization reduces discrepancies between training and test errors for improved model generalization.
- Proper regularization enhances model performance on test data points, addressing overfitting concerns effectively.
New Section
The speaker reflects on the efficacy of the introduced concepts while highlighting a need for deeper understanding beyond mere validation.
Reflection on Formulation
- Despite successful outcomes, there is a quest for deeper comprehension beyond empirical validation in understanding model mechanisms.