RN2024 - Clase02_a
Teorema de Cenco y Almacenamiento de Modelos
Resumen de la Sección: En esta sección, se aborda el teorema de Cenco en el contexto del aprendizaje automático, así como la importancia del almacenamiento y recuperación de modelos entrenados para su uso futuro.
Teorema de Cenco
- El teorema de Cenco es mencionado en relación con el aprendizaje automático, aunque no es familiar para todos los estudiantes.
- Se destaca que el teorema es más teórico que práctico, pero puede ser interesante conocerlo y explorarlo en futuras clases.
Almacenamiento de Modelos
- Se discute la relevancia del almacenamiento y recuperación de modelos entrenados para su posterior uso en producción.
- Es fundamental guardar tanto la arquitectura como los pesos asociados a un modelo entrenado para poder utilizarlo eficazmente en diferentes contextos.
Pausa durante Entrenamiento y Embeber Modelos
Resumen de la Sección: En esta parte se explora cómo pausar durante el entrenamiento, reutilizar modelos previamente entrenados y embeberlos en aplicaciones para su implementación práctica.
Pausa durante Entrenamiento
- Se plantea la posibilidad de pausar el entrenamiento de un modelo complejo si se percibe que las épocas establecidas no son suficientes para lograr un rendimiento óptimo.
- En lugar de reiniciar desde cero, se sugiere utilizar los pesos del modelo actualizado como punto inicial para un nuevo ciclo de entrenamiento.
Embeber Modelos en Aplicaciones
- Para poner en producción un modelo, es necesario integrarlo en una aplicación específica, lo cual implica desarrollar habilidades adicionales relacionadas con programación y desarrollo de aplicaciones.
- Se menciona la opción de guardar únicamente la arquitectura del modelo en formato JSON o los pesos según las necesidades específicas del proyecto.
Guardado y Recuperación Eficiente
Resumen de la Sección: Aquí se detalla cómo guardar eficientemente modelos mediante el almacenamiento tanto de su arquitectura como sus pesos asociados.
Guardado Eficiente
- Para conservar solo la arquitectura del modelo, se debe solicitar al modelo que proporcione un string JSON que luego puede guardarse convencionalmente utilizando herramientas estándar como Python.
Entrenamiento de Redes Neuronales
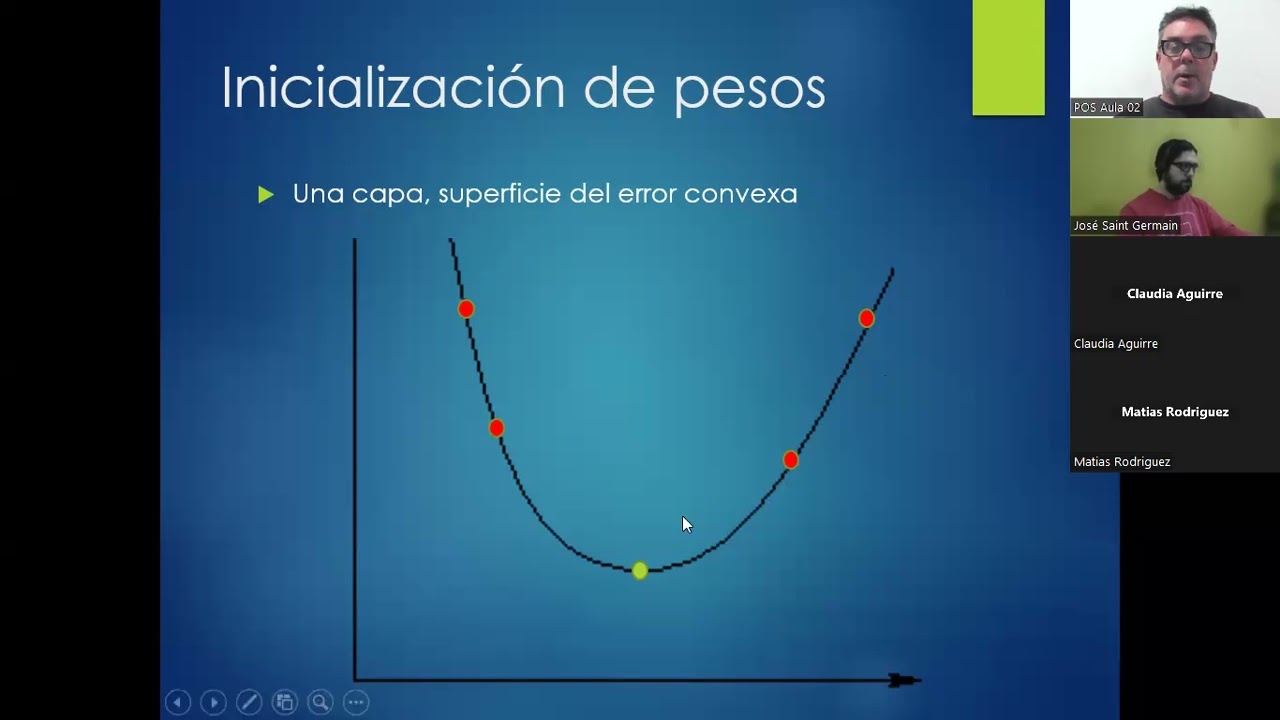
Resumen de la Sección: En esta sección, se aborda la importancia del entrenamiento de redes neuronales, centrándose en el estado inicial de los pesos y su impacto en la convergencia hacia mínimos locales y globales.
Estado Inicial de los Pesos
- El valor inicial de los pesos es crucial en el entrenamiento de una red neuronal, ya que afecta la convergencia hacia mínimos locales y globales.
- Dependiendo del punto inicial, se puede alcanzar un mínimo global o quedar atrapado en mínimos locales debido a la complejidad de las superficies de error en problemas reales.
- No siempre es necesario alcanzar el mínimo global; llegar a un mínimo local puede ser suficiente según las necesidades del problema.
Inicializadores de Pesos
- Existen inicializadores como Glorot que buscan evitar derivadas muy pequeñas o grandes al seleccionar aleatoriamente los pesos para facilitar la convergencia durante el entrenamiento.
- Los inicializadores buscan mantener los pesos acotados para evitar estancamientos o saltos excesivos durante el proceso iterativo.
Funcionamiento de Inicializadores
- Los pesos se inicializan para garantizar valores cercanos entre capas y controlar las derivadas, lo que favorece una convergencia estable durante el entrenamiento.
Recta 45 y Valores de Gradientes
Resumen de la Sección: En esta sección, se discute la distribución de los valores de los gradientes en las capas de una red neuronal, destacando el control en las primeras capas y cierto descontrol en las últimas.
Distribución de Valores
- Los valores de los gradientes en las primeras capas están bien controlados.
- En las últimas capas, algunos valores se disparan un poco, pero en general se logra un buen control.
Inicializadores y Roles en Capas Neuronales
Resumen de la Sección: Aquí se aborda la importancia de los inicializadores en las capas neuronales y cómo estos afectan a los pesos y bias.
Inicializadores por Capa
- Es crucial asignar un inicializador a cada capa para controlar su comportamiento.
- Se puede especificar el inicializador tanto para los pesos (kernel) como para los bias (bias).
Elección de Inicializadores Diferentes
Resumen de la Sección: Se explora la posibilidad de elegir distintos inicializadores para pesos y bias dentro de una misma capa neuronal.
Personalización del Inicializador
- Al crear una capa con múltiples neuronas, es posible definir diferentes inicializadores para pesos y bias.
- Ejemplo: Asignar ceros a los bias y valores aleatorios basados en distribución normal a los pesos.
Regularización de Pesos
Resumen de la Sección: La regularización busca mantener el equilibrio entre overfitting y underfitting al controlar el crecimiento excesivo o disminución nula de los pesos.
Control del Modelo
- La regularización evita que los pesos se disparen hacia infinito o tiendan a cero, manteniendo así un modelo generalizado.
Regularización en Redes Neuronales
Resumen de la Sección: En esta sección, se discute el concepto de regularización en redes neuronales y cómo afecta a los parámetros de la red para evitar el sobreajuste.
Regularización de Parámetros
- A medida que el valor de lambda crece, las muestras pueden ser mal clasificadas al no haber una separación clara.
- La regularización puede aplicarse de diferentes maneras a los parámetros W y B para minimizar errores.
- El término bas afecta la ordenada del origen en la ecuación de la recta, influyendo en su ajuste.
- Regularizar solo los pesos W permite que la recta se ajuste sin forzarla a pasar por el origen.
Importancia de Regularización
- No es común regularizar los sesgos B ya que puede limitar la flexibilidad del modelo.
- Forzar ciertos comportamientos mediante regularización puede obstaculizar el aprendizaje efectivo del modelo.
Capas y Regularizadores en Redes Neuronales
Resumen de la Sección: Aquí se explora cómo aplicar regularizadores a diferentes capas en redes neuronales para controlar el ajuste del modelo.
Uso de Regularizadores
- Es posible definir regularizadores capa por capa para los pesos W y sesgos B según las necesidades del diseño.
- La combinación de errores propios con términos regulares L1 y L2 permite un control más preciso sobre el ajuste del modelo.
Expansión de Capas
- A lo largo del tiempo, han surgido nuevas ideas sobre capas adicionales más allá de las densas y convolucionales tradicionales.
Capa Dropout en Redes Neuronales
Resumen de la Sección: Se aborda el uso y funcionamiento de la capa Dropout para mejorar el rendimiento durante el entrenamiento.
Funcionalidad de Dropout
- La capa Dropout busca anular ciertas neuronas durante el entrenamiento para fomentar robustez ante variaciones.
- Al desactivar selectivamente neuronas, se promueve una adaptabilidad mayor ante escenarios cambiantes.
Implementación Práctica
Arquitectura y Probabilidad de Neuronas Activas
Resumen de la Sección: En esta sección, se discute cómo la arquitectura neuronal permanece constante para evitar el caos, mientras que las probabilidades de activación de las neuronas varían.
Arquitectura Constante y Cambio en Probabilidades
- La probabilidad de que una neurona esté activa es crucial, con un promedio del 66% para tres neuronas implicando que dos estarán activas.
- En capas con muchas neuronas, es improbable que todas estén inactivas en una época, lo que garantiza diversidad en la actividad neuronal.
- La posibilidad de tener todas las neuronas apagadas o encendidas simultáneamente es extremadamente baja.
Impacto del Dropout en la Predicción
Resumen de la Sección: Aquí se explora cómo el dropout afecta a las neuronas durante el entrenamiento y la predicción en redes neuronales.
Efecto del Dropout
- Durante el entrenamiento, las neuronas se acostumbran a ciertas activaciones debido al dropout.
- En predicción, si se utilizan pesos guardados, se aplica una máscara basada en las probabilidades usadas durante el entrenamiento.
- El debate sobre la efectividad del dropout persiste entre los expertos.
Ventajas y Desventajas del Dropout
Resumen de la Sección: Se analizan los argumentos a favor y en contra del uso del dropout como técnica regularizadora en redes neuronales.
Debate sobre Dropout
- Existe un debate continuo sobre si el dropout es beneficioso o no dentro del contexto de redes neuronales.
- El dropout ofrece ventajas computacionales al ser liviano y proporcionar cierta regularización a través de su mecanismo simple.
Regularización y Superficies de Error
Resumen de la Sección: Se profundiza en cómo el dropout influye en la regularización neuronal y modifica las superficies de error durante el entrenamiento.
Regularización Dinámica
- El uso estratégico del dropout permite modificar constantemente las superficies de error, aumentando la exploración hacia mínimos locales más óptimos.
Análisis Detallado de la Transcripción
Redes Neuronales y Técnicas de Regularización
Resumen de la Sección: En esta sección, se discuten conceptos clave relacionados con redes neuronales y técnicas de regularización como dropout y batch normalization.
- Las redes neuronales pueden comportarse de manera aleatoria al inicio debido a la eliminación constante de conexiones (dropout), lo que introduce un elemento azaroso en el proceso.
- El objetivo es que las salidas aprendan del procesamiento previo en la red, por lo que el valor del dropout debe ser pequeño para permitir cierto ruido controlado.
- El dropout implica desactivar un porcentaje pequeño de neuronas durante el entrenamiento para introducir ruido controlado sin perder información importante.
- La capa de batch normalization normaliza los datos para estabilizar el entrenamiento, evitando problemas como gradientes explosivos o desvanecientes.
Normalización y Transformación de Datos
Resumen de la Sección: Aquí se profundiza en cómo la normalización afecta a los datos y su transformación en diferentes capas de una red neuronal.
- La normalización z transforma los datos para centrarlos en una media y varianza específicas, facilitando el procesamiento uniforme en las capas subsiguientes.
- Al pasar los datos entre capas, estos cambian dimensionalidad, lo que puede requerir nueva normalización para mantener la coherencia en el espacio transformado.
- La batch normalization recalcula medias y desviaciones estándar por lote, adaptándose a las variaciones internas del modelo durante el entrenamiento.
Impacto y Consideraciones Finales
Resumen de la Sección: Se abordan aspectos críticos sobre cómo las técnicas mencionadas influyen en el aprendizaje y estabilidad del modelo.
- Los cambios constantes en la distribución de muestras debido a la normalización pueden influir en la superficie del error, impactando directamente en el rendimiento del modelo.
- La normalización puede homogeneizar muestras distintas, lo cual puede confundir a las capas posteriores al hacerlas percibir como similares cuando no lo son realmente.
Trabajo con Capas Convolucionales
Resumen de la Sección: En esta sección, se aborda el funcionamiento de las capas convolucionales en redes neuronales, destacando la diferencia entre cómo afectan a la entrada y salida de las capas.
Funcionamiento de las Capas Convolucionales
- Se menciona que tanto el dropout como la batch normalization impactan la entrada y salida de las capas adyacentes.
- Se introducen las capas convolucionales 1D y 3D, resaltando su aplicación en matrices y filtros para procesar datos en dos dimensiones.
- Explicación detallada sobre cómo los filtros o kernels se desplazan en dos dimensiones para realizar transformaciones en matrices.
- La salida de una convolución 2D es una matriz más pequeña que barre la matriz original generando un solo dato por barrido.
Dimensionalidad en Convoluciones
- Se discute cómo trabajar con imágenes RGB implica operar con tres canales, aumentando la dimensionalidad del kernel y efectos resultantes.
- Analogía visual sobre el movimiento del filtro en convoluciones 3D, explicando por qué sigue siendo considerado un proceso 2D.
Convolutional Layers: 1D and 3D
Sección Resumida: En esta parte se profundiza en las capas convolucionales 1D y 3D, explorando su aplicación en diferentes contextos y dimensiones.
Capas Convolucionales Unidimensionales
- La convolución 1D implica trabajar con vectores unidimensionales donde el filtro se mueve en una sola dirección para generar valores individuales.
- Explicación sobre cómo múltiples kernels pueden dar lugar a salidas tridimensionales al combinar resultados de distintas convoluciones unidimensionales.
Aplicaciones Específicas
- Uso común de capas convolucionales 1D para series temporales y señales de audio debido a su capacidad para procesar datos secuenciales eficientemente.
- Comparativa entre convoluciones 2D y 1D, destacando diferencias clave en movimientos del filtro y resultados obtenidos según la dimensionalidad del input.
Convolución Tridimensional
Resumen General: Esta sección explora el concepto de convolución tridimensional, enfocándose en aplicaciones específicas como videos compuestos por múltiples fotogramas.
Convolutional Layers: 3D
- Introducción a la idea de trabajar con entradas tridimensionales, especialmente relevantes para videos que consisten en una secuencia temporal de fotogramas.
Análisis de Convoluciones en 3D
Resumen de la Sección: En esta sección, se explora el concepto de convoluciones en 3D y cómo aplicarlo a videos con múltiples dimensiones.
Concepto de Convolución en 3D
- La convolución en 3D implica un filtro que se mueve en tres dimensiones: izquierda-derecha, arriba-abajo y en profundidad.
- Al aplicar una convolución 3D a un video, la salida también será tridimensional.
Consideraciones con Videos Multicanal
- Cuando se trabaja con videos multicanal, se introduce una cuarta dimensión que representa los distintos canales del video.
- Para mantener la coherencia, el kernel replicará tantos canales como tenga la entrada original.
Desbalance de Clases y Ajuste de Errores
Resumen de la Sección: Aquí se aborda el desbalance de clases y cómo ajustar los errores para mejorar el rendimiento del modelo.
Desbalance de Clases
- El desbalance de clases es común en datasets y puede afectar el rendimiento del modelo.
- Estrategias como oversampling o subsampling ayudan a equilibrar las muestras entre las clases.
Ajuste de Errores por Clase
- Es posible asignar pesos diferentes a los errores cometidos en cada clase para priorizar ciertas predicciones sobre otras.
Análisis Detallado del Entrenamiento de Redes Neuronales
Resumen de la Sección: En esta sección, se profundiza en las estrategias para el entrenamiento de redes neuronales, abordando temas como el balanceo de clases, pesos para cada clase, optimizadores y la determinación del número adecuado de épocas.
Balanceo de Clases y Pesos
- Se discute la posibilidad de realizar oversampling o subsampling en las clases o ajustar los pesos para cada clase en el dataset.
- Ejemplo con dos clases (A y B) donde se asignan pesos diferentes a cada una durante el entrenamiento.
- Uso del parámetro Class weight para definir los pesos de las clases durante el entrenamiento.
Optimización y Regularización
- Explicación sobre cómo se penalizan los errores en función de los pesos asignados a cada clase.
- Importancia de la magnitud del gradiente en el proceso de optimización y cómo influye en la velocidad del aprendizaje.
- Descripción del optimizador Adagrad que normaliza la magnitud del gradiente para equilibrar direcciones y magnitudes.
Optimizadores Avanzados
- Funcionamiento del optimizador Adam que combina gradientes y momentos para actualizar los valores durante el entrenamiento.
- El valor alfa (learning rate) en Adam es menos relevante debido a su capacidad adaptativa, aunque sigue siendo un hiperparámetro ajustable.
Determinación del Número de Épocas
- Elección entre distintos optimizadores al compilar el modelo, como Adam o Adagrad.
Plataforma de Entrenamiento y Callbacks
Resumen de la Sección: En esta sección, se discute el uso de callbacks en el entrenamiento de modelos. Los callbacks son funciones que se activan durante el entrenamiento para monitorear diferentes eventos y realizar acciones específicas.
Plancha o Overfitting
- Los callbacks son esenciales para evitar situaciones como el overfitting, donde la curva de testing muestra un aumento repentino.
- Se menciona la importancia del callback
colback, que consiste en llamadas a funciones propias que ocurren durante el entrenamiento.
Definición y Uso de Funciones Propias
- Se destaca la posibilidad de definir funciones propias, como
def on EPOC end, que se activan al finalizar una época.
- Estas funciones permiten medir y controlar aspectos clave del modelo durante diferentes etapas del entrenamiento.
Monitoreo y Detención del Entrenamiento
Resumen de la Sección: En este segmento, se profundiza en cómo los callbacks pueden utilizarse para monitorear eventos específicos durante el entrenamiento y detenerlo según ciertos criterios predefinidos.
Monitoreo con Callbacks
- Los callbacks ofrecen la posibilidad de monitorear diversos eventos durante el entrenamiento, como errores elevados en muestras particulares.
- Se menciona un callback propio de Keras llamado
ear stoppingque detiene el entrenamiento cuando no hay cambios significativos en ciertas métricas.
Criterios de Detención
- Se establece la importancia de definir criterios claros para detener el entrenamiento, como la paciencia (cantidad de épocas sin cambios significativos).
- Ejemplificando con un caso particular, se explica cómo detener el entrenamiento si durante cinco épocas seguidas no hay mejoras sustanciales en las métricas evaluadas.
Arquitecturas y Competición ImageNet
Resumen de la Sección: Aquí se aborda la relevancia de las arquitecturas en machine learning y cómo estas han sido desarrolladas a través de pruebas exhaustivas. Además, se menciona la competición ImageNet como fuente clave para evaluar modelos.
Desarrollo Arquitectónico
- Las arquitecturas en machine learning son construcciones complejas formadas por capas interconectadas que buscan resolver problemas específicos.
- El proceso detrás del desarrollo arquitectónico implica ensamblar capas como bloques Lego para crear estructuras efectivas para cada problema abordado.
Competición ImageNet
- La competición ImageNet ha sido fundamental en impulsar avances en modelos ML al evaluar su desempeño con una base extensa de datos clasificados.
Innovación en Redes Neuronales Convolucionales
Resumen de la Sección: En esta sección, se aborda la evolución de las redes neuronales convolucionales desde el concepto de bloques hasta su aplicación en modelos específicos.
Evolución de las Redes Neuronales Convolucionales
- En los años 80 se hablaba de neuronas, luego se pasó a capas y posteriormente a bloques de capa en la construcción de redes neuronales.
- Los primeros modelos propuestos incluyeron seis variantes (A, B, C, D, E) con entradas de imágenes de 224x224 píxeles.
- La arquitectura más liviana contaba con 11 capas, mientras que la más pesada llegaba a tener 19 capas.
- La idea clave era apilar convoluciones una tras otra para lograr el éxito en el diseño de redes neuronales convolucionales.
Implementación y Entrenamiento
- Se destaca cómo se logra la reducción espacial en las imágenes a través del proceso de convolución hasta llegar al "flaten".
- Se menciona que es posible replicar este proceso utilizando bloques convolucionales y max pooling repetidamente para construir redes complejas.
- Las redes resultantes pueden tener millones de parámetros, lo que implica un espacio dimensional significativo para optimizar el modelo durante el entrenamiento.
Uso Práctico y Personalización de Arquitecturas Preentrenadas
Resumen de la Sección: Aquí se explora cómo utilizar arquitecturas preentrenadas como base para adaptarlas a necesidades específicas.
Personalización y Adaptación
- Se detalla cómo acceder y utilizar una red preentrenada como VGG16 con diferentes configuraciones mediante parámetros específicos.
- Es posible modificar aspectos como las capas finales o incluso entrenar desde cero ajustando los pesos según los requerimientos del problema.
- Cambiar el tamaño o canales de entrada afecta directamente la compatibilidad con los pesos preentrenados y la cantidad final de clases del modelo.
Uso Avanzado y Transferencia
- Si se desea mantener la estructura original pero cambiar detalles como el número de clases, es necesario ajustar ciertas partes sin alterar todo el modelo.
Clasificación con Global Average Pooling
Resumen de la Sección: En esta sección, se explora el uso de Global Average Pooling en el proceso de clasificación.
Proceso de Clasificación con Global Average Pooling
- La red neuronal utilizada para clasificar emplea una capa densa con Softmax al final.
- El Global Average Pooling se encarga de realizar la reducción espacial sin utilizar Max Pooling ni Stride.
- Al ajustar los strides a valores más altos, se logra una reducción espacial efectiva.
- Esta técnica implica menos parámetros en comparación con otros métodos convencionales.
- El Global Average Pooling calcula un promedio por canal, simplificando la información a un vector para la capa final.
Ventajas y Aplicaciones del Global Average Pooling
- Permite obtener un vector que facilita la clasificación directa sin necesidad de capas densas adicionales.
- Los valores resultantes tras el proceso pueden alimentar directamente una función Softmax para obtener probabilidades de clase.
Importancia y Funcionamiento del Global Average Pooling
- La capa final utiliza los últimos feature maps para determinar las clases, optimizando la predicción.
- El proceso genera valores entre 0 y 1, indicando las probabilidades asociadas a cada clase.
Flexibilidad y Efectividad del Global Average Pooling
- La técnica produce salidas específicas que permiten interpretar fácilmente las predicciones realizadas por la red neuronal.
Convoluciones en Redes Neuronales Convolucionales
Resumen de la Sección: En esta sección, se discute el concepto de convoluciones en redes neuronales convolucionales, centrándose en modelos como MobileNet y Deepwise.
Convoluciones en Redes Neuronales
- MobileNet: Diseñada para ser ligera en memoria y CPU, ideal para dispositivos móviles.
- Estructura de las redes: Mayormente compuestas por capas convolucionales hasta llegar a una capa softmax. Introducción de la convolución Deepwise.
- Convolución separable en profundidad: Aplica un kernel a cada canal de entrada, reduciendo la cantidad de kernels necesarios.
- Capa Deepwise: Aplica un kernel a cada capa de entrada, generando múltiples feature maps como salida.
- Ventajas de Deepwise: Permite aplicar un kernel canal a canal, reduciendo la cantidad total de kernels necesarios.
Innovación en Arquitecturas de Redes Neuronales
Resumen de la Sección: Aquí se explora el concepto innovador detrás del bloque Inception introducido por Google Net.
Bloque Inception y Google Net
- Google Net (Inception): Introduce el bloque Inception que trabaja en paralelo para aprender características distintas simultáneamente.
- Arquitecturas lineales vs. Inception: Contraste entre arquitecturas lineales tradicionales y el bloque Inception que busca diversificar respuestas.
Salidas y Convolución
Resumen de la Sección: En esta sección, se discute el proceso de convolución y cómo las salidas se concatenan para formar un tensor.
Proceso de Convolución
- La convolución implica combinar diferentes capas (C3 por 3, C5 por 5, C1 por 1 y MP1) para formar un tensor.
- Al concatenar estas salidas, se obtiene un resultado que modifica la imagen original.
Modificación de Imágenes en Convolución
Resumen de la Sección: Se explora cómo la convolución modifica las imágenes al sumar valores a los píxeles.
Modificación de Imágenes
- En la convolución, se suma el mismo valor a todos los píxeles, lo que altera el brillo y contraste de la imagen.
- Esta modificación afecta a todos los píxeles excepto cuando el valor es cero, manteniendo así la misma imagen pero con cambios en brillo.
Aumento de Canales en Convolución
Resumen de la Sección: Se analiza cómo aumentar canales en una convolución utilizando filtros específicos.
Aumento de Canales
- Al aplicar una convolución uno por uno con más canales, se logra tener una misma imagen con variaciones en brillo en múltiples canales.
- Este método ayuda a no modificar demasiado la imagen espacialmente mientras se incrementan los canales disponibles.
Estructura del Modelo Inception
Resumen de la Sección: Se detalla la estructura del modelo Inception y cómo maneja las salidas intermedias.
Estructura del Modelo
- El modelo Inception utiliza bloques sucesivos para generar múltiples salidas intermedias antes de llegar a una salida final.
Resumen Detallado
Salida y Canales de Entrada
- La salida es un solo canal, independientemente de la cantidad de canales de entrada que tenga un kernel.
Modelos Utilizados
- Inception en su versión 3 y ResNet son modelos utilizados, con ResNet teniendo varias versiones, incluida una con 152 capas.
Bloquecitos de Cuello de Botella
- Se introducen los "bloquecitos" de cuello de botella para reducir la cantidad de parámetros en comparación con una sola convolución.
Reducción de Canales
- Al aplicar un kernel a una entrada con múltiples canales, se obtiene una salida con un solo canal, lo que permite reducir la cantidad de parámetros.
Uso Eficiente de Parámetros
- Empleando bloques convolucionales específicos, se logra mantener la misma cantidad de canales a la entrada y salida utilizando menos parámetros.
Bloquecito Residual
- El bloque residual busca mantener la misma cantidad de canales a la entrada y salida mientras suma aritméticamente la entrada original al resultado final.
Modificaciones en las Capas
- Conceptualmente, el bloque residual busca aprender qué modificaciones realizar en la imagen original para minimizar el error en la salida.
Aprendizaje del Modelo
- El bloque residual intenta aprender las modificaciones necesarias para que el modelo genere salidas con el menor error posible.
Visualización y Entrenamiento
Resumen Detallado
Redes Residuales y Bloques Bottleneck
Descripción de la Sección: En esta sección, se discute el concepto de redes residuales y bloques bottleneck en la arquitectura de ResNet.
- Se explica que en ResNet se utiliza un bloque bottleneck que comienza con una entrada a la cual se aplican varias convoluciones en secuencia.
- La salida del bloque bottleneck es el resultado de una suma aritmética entre la entrada original y el residual obtenido después de las convoluciones.
- El objetivo del bloque bottleneck es reducir la cantidad de parámetros para aprender a modificar la imagen original y disminuir el error en la salida.
Tamaño de Entrada y Estrategias para Adaptación
Descripción de la Sección: Aquí se aborda cómo manejar tamaños diferentes de imágenes al utilizar una red entrenada como ResNet.
- Se menciona que las imágenes deben tener un tamaño específico, como 224x224, debido a su uso en ImageNet.
- Ante imágenes con dimensiones distintas, se discute sobre estrategias como hacer zoom in o zoom out para ajustarlas al tamaño requerido por la red.
- Otras opciones incluyen agregar padding a las imágenes más pequeñas o realizar un agrandamiento con posible pérdida de calidad.
Adaptación del Modelo Base y Aprendizaje Espacial
Descripción de la Sección: Aquí se profundiza sobre cómo adaptar modelos preentrenados a diferentes tamaños de entrada.
- Una estrategia sugerida es agregar una capa al modelo base que ajuste las dimensiones de entrada sin perder información relevante.
- Aunque va contra lo convencional, esta adaptación permite que el modelo aprenda los cambios necesarios en el factor espacial para minimizar errores.
Anuncios Finales y Próximas Clases
Descripción de la Sección: En este segmento, se realizan anuncios sobre horarios y actividades futuras relacionadas con las clases.
- Se informa sobre cambios en los horarios para facilitar la participación activa durante las clases virtuales.
- Los viernes habrá sesiones dedicadas a resolver dudas, mientras que los sábados iniciarán más tarde para permitir mayor disponibilidad horaria.