Introduction to Amazon SageMaker
Amazon SageMaker: Building Machine Learning Models
Introduction to Amazon SageMaker
- Amazon SageMaker is designed to assist data scientists and developers in preparing data, building, training, and deploying machine learning models efficiently.
- It integrates purpose-built capabilities that enable the creation of highly accurate models that improve over time without the burden of managing ML environments.
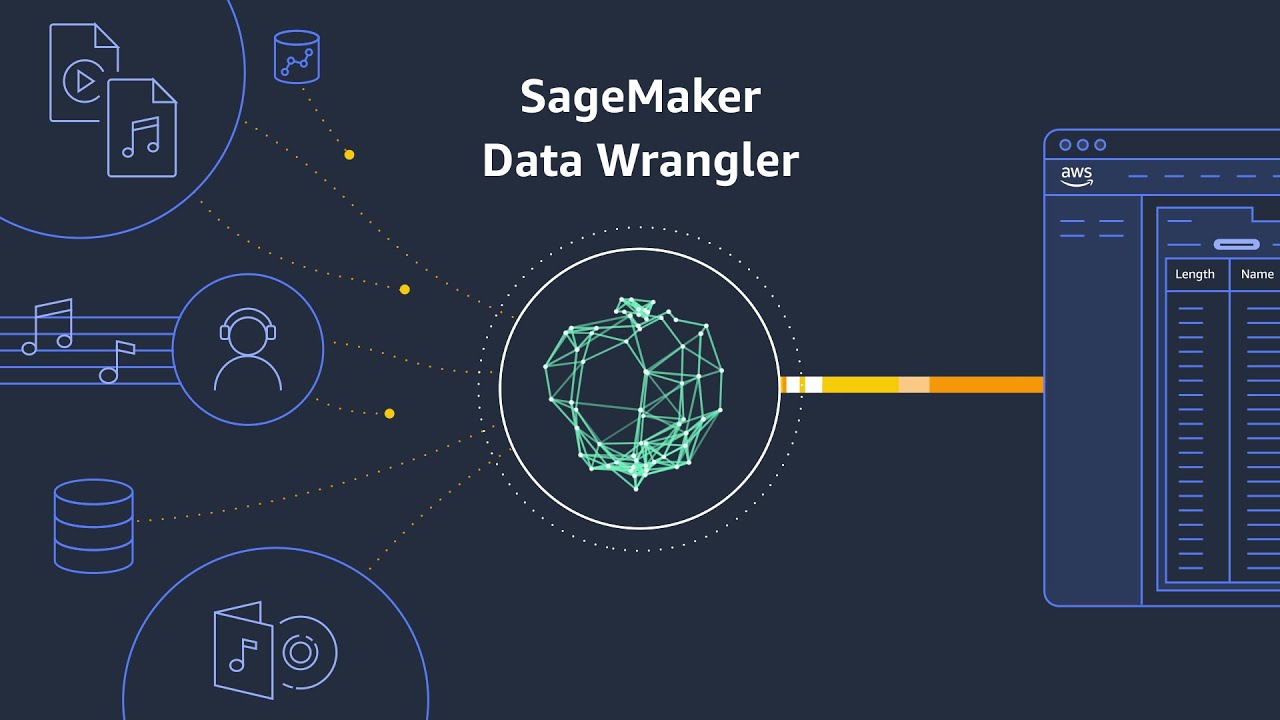
Data Preparation for Model Training
- To create a musical playlist tailored to listener preferences, a substantial amount of data is required. SageMaker facilitates easy connection and loading of data from sources like Amazon S3 and Redshift.
- Raw data often lacks sufficient information for model training; thus, feature engineering is essential to convert raw data into useful features. This process can consume over 80% of model development time.
Feature Engineering with SageMaker
- SageMaker Data Wrangler allows users to quickly convert and transform raw tabular data into features, significantly reducing the time needed for this task.
- Features can be saved in the SageMaker Feature Store for easy management, enabling teams to create multiple versions and descriptions while facilitating searchability.
Ensuring Balanced Training Data
- Using SageMaker Clarify helps ensure that training datasets are well-balanced across different feature values, which enhances model accuracy across various subsets (e.g., musical genres).
- Clarify also enables inspection of individual predictions to assess how each feature influences outcomes, ensuring no over-reliance on underrepresented features.
Continuous Improvement of Models
- Machine learning models can evolve by integrating insights from tools like SageMaker Clarify and Debugger, allowing systematic identification and removal of errors or inefficiencies.