大语言模型微调之道8——建议和实用技巧
Getting Started and Advanced Training Methods
In this section, practical steps for fine-tuning models are discussed along with a sneak peek into advanced training methods.
Practical Steps for Fine-Tuning
- Collect data related to tasks' inputs and outputs and structure it accordingly. If data is insufficient, generate more or use prompt templates.
- Start by fine-tuning a small model (400 million to 1 billion parameters) to gauge performance sensitivity to data volume. Vary the data amount given to understand its impact on the model.
- Evaluate the model's performance to identify strengths and weaknesses. Collect more data based on evaluation insights for further model improvement.
Increasing Task Complexity
- Harder tasks like writing tasks (e.g., emails, code) require larger models due to producing more tokens, making them challenging for models.
- Combining tasks or asking models to perform multiple actions simultaneously increases task complexity, necessitating larger models for handling such challenges efficiently.
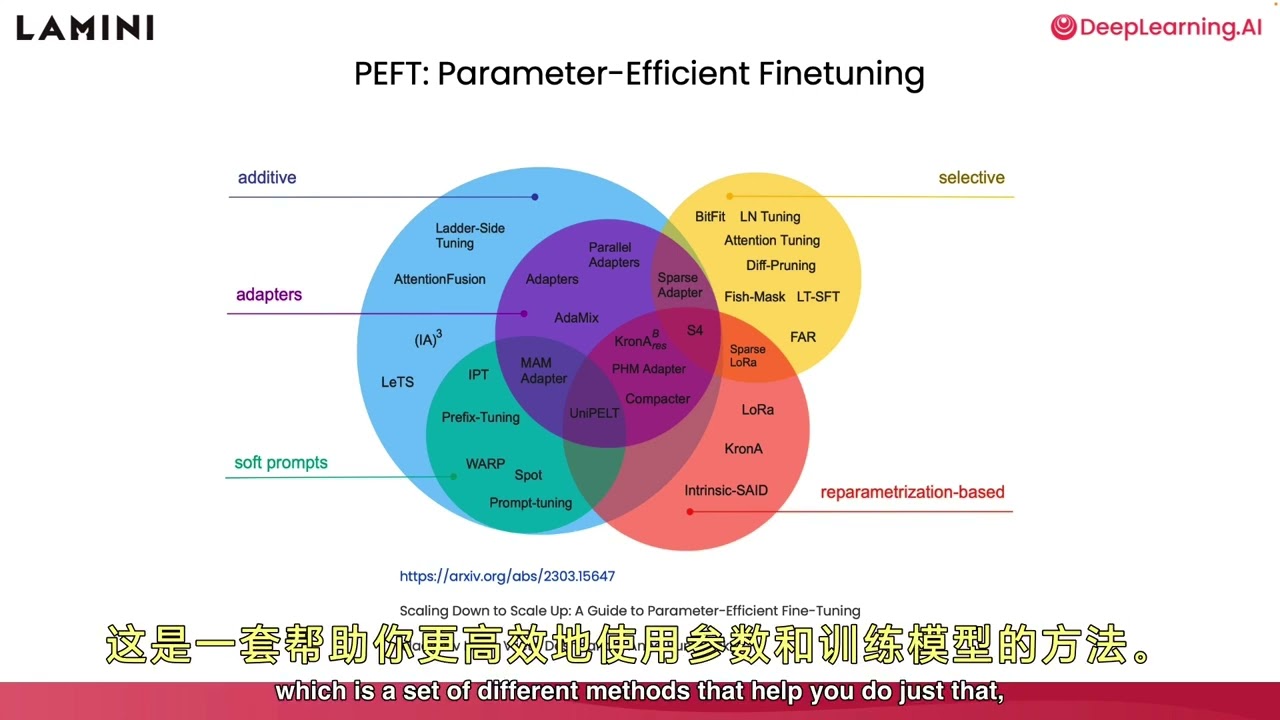
Compute Requirements and Parameter Efficient Fine-Tuning
This section delves into compute requirements for running models efficiently and introduces parameter-efficient fine-tuning methods like LORA.
Compute Requirements
- Optimal hardware choices are crucial; starting with a 1v100 GPU (e.g., available in AWS) can support running 7 billion parameter models for inference but only 1 billion parameter models for training due to memory constraints.