大语言模型微调之道4——指令微调
Instruction Fine-Tuning: Enhancing Models with Chatting Powers
In this section, the concept of instruction fine-tuning is introduced, focusing on how it transforms models like GPT-3 into chatbots by teaching them to follow instructions effectively.
Instruction Fine-Tuning Explained
- Instruction fine-tuning teaches models to follow instructions, making them more chatbot-like and user-friendly.
- Leveraging existing datasets such as FAQs or customer support conversations is crucial for instruction following tasks.
- Converting data into question-answer or instruction-following formats using prompt templates is a viable option if specific datasets are unavailable.
Benefits and Applications of Fine-Tuning Models
This segment delves into the advantages of fine-tuning models, particularly in enabling them to exhibit new behaviors based on pre-existing knowledge.
Advantages of Fine-Tuning
- Fine-tuning imparts new behaviors to models beyond basic question-answer pairs, allowing for broader applications like code-related queries.
- The cost-effectiveness of fine-tuning for specialized tasks like code-related questions is highlighted through leveraging pre-existing model knowledge.
Fine-Tuning Process and Data Preparation
This part outlines the iterative process involved in fine-tuning models, emphasizing data preparation as a critical step for tailoring the model's performance.
Steps in Fine-Tuning
- The three main steps in fine-tuning are data preparation, training, and evaluation, with an emphasis on refining data iteratively.
- Data preparation plays a pivotal role in customizing the model for specific fine-tuning tasks before proceeding with training and evaluation processes.
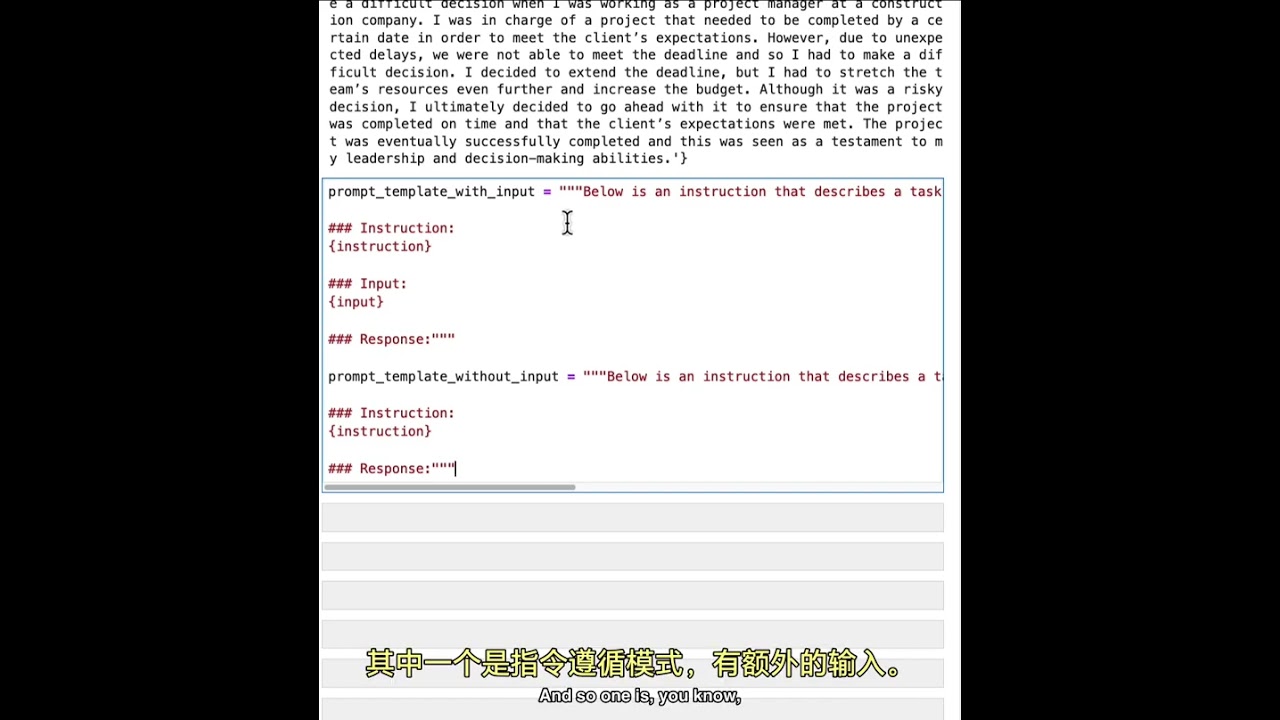
Exploration of Alpaca Dataset for Instruction Tuning
Here, a practical demonstration using the Alpaca dataset showcases how instruction tuning can enhance model performance compared to non-instruction tuned models.
Alpaca Dataset Exploration
- Importing libraries and loading the Alpaca dataset demonstrate structured data suitable for instruction tuning tasks.
- The Alpaca dataset features prompt templates that guide model behavior based on different types of inputs provided.
Model Comparison: Instruction Tuned vs. Non-Tuned
A comparison between instruction tuned and non-tuned models underscores the significant performance improvements achieved through instruction tuning methodologies.
Model Performance Evaluation
Parameter Models and Model Comparison
In this section, the speaker discusses different parameter models, focusing on a 70 billion parameter model and a smaller 70 million parameter model. The comparison between these models is explored through running inference on text data.
Exploring Different Parameter Models
- The Chachi beauty model is estimated to have around 70 billion parameters, signifying its large scale.
- Introducing a smaller model with 70 million parameters that has not been fine-tuned for instruction.
- Loading two different models to process data and run inference, showcasing the Pythia-70 tag for the 70 million parameter model.
Model Fine-Tuning and Inference Results
This part delves into running inference using the 70 million parameter model that lacks fine-tuning. It demonstrates how the model processes a question from a dataset and provides an answer based on its current state.
Running Inference with Unfine-Tuned Model
- Utilizing the unfine-tuned 70 million parameter model to generate technical documentation or user manuals for software projects.
- Presenting a sample question from the dataset regarding generating documentation.
- Despite recognizing keywords like "documentation," the model's response deviates significantly from expectations due to lack of fine-tuning.
Fine-Tuned Model Performance Comparison
A comparison is made between the unfine-tuned model used previously and a fine-tuned version that aligns more closely with expected behavior. The performance difference in answering questions related to generating technical documentation is highlighted.
Contrast Between Unfine-Tuned and Fine-Tuned Models
- Illustrating how the unfine-tuned model struggles to provide accurate responses due to inadequate training.
- Previewing improved performance by loading and running questions through a fine-tuned version of the same model.