Video description
大语言模型微调之道8——建议和实用技巧
#大语言模型微调之道
大家好!这是我们的最后一课,将分享如何开始微调大型语言模型的一些建议和实用技巧。
首先,确定你的任务并收集相关数据。如果数据不足,可以生成或使用模板。建议先使用4亿至10亿参数的小模型进行尝试。然后评估模型并收集更多数据进行改进。
随着任务的复杂度增加,你可能需要更大的模型。比如,写作任务(如聊天、写邮件、写代码)比阅读任务更难,因为它们产生更多的标记。
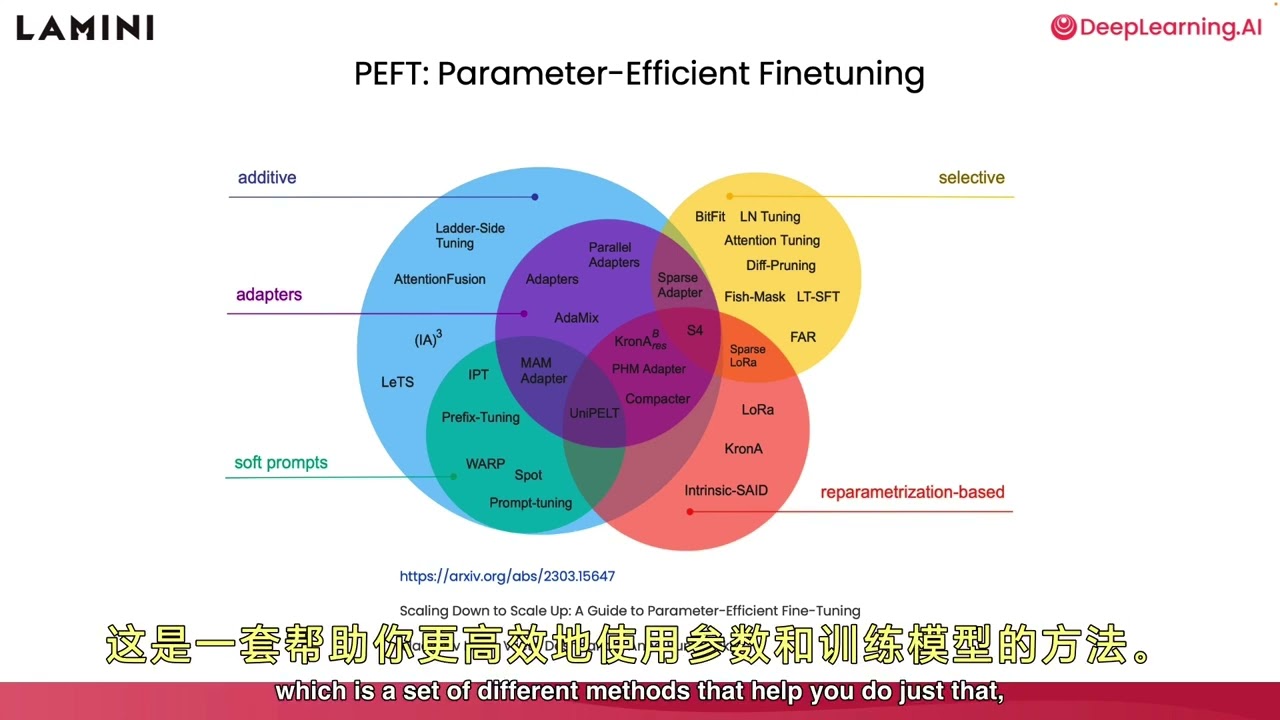
对于大型模型的训练,我们还介绍了PEFT(参数高效微调)方法,特别是LoRA(低等级适应)。LoRA可以大幅度减少训练参数,使GPU内存需求减少3倍。LoRA的核心是在模型的某些层上训练新权重,而不改变原始权重。这种方法尤其适合适应新任务。
希望大家从这节课中学到有用的信息!
课程地址:https://www.deeplearning.ai/short-courses/finetuning-large-language-models/
YouTube:https://www.youtube.com/watch?v=3apAPNXogAQ&list=PLiuLMb-dLdWKtPM1YahmDHOjKN_a2Uiev
B站:https://www.bilibili.com/video/BV1Lu4y1X7DZ/