Meet ghk ihio kgk Google Chrome 2026 04 07 19 37 37
Introducción a los Tipos de Datos y Calidad
Tipos de Datos
- Se mencionan varios tipos de datos importantes: numéricos, categóricos, ordinales, texto y fecha. Estos son fundamentales en el análisis de datasets.
- Un error común es calcular promedios en datos que no son adecuados para ello, como en el caso de ciudades.
Calidad de Datos
- La calidad de los datos es crucial; si se tiene "basura", se obtienen resultados erróneos. Problemas comunes incluyen valores faltantes, duplicados e inconsistencias.
- Ejemplos típicos de errores incluyen precios negativos o nombres inconsistentes (como ciudades), que pueden afectar la calidad del análisis.
Dimensiones de Calidad
- Las dimensiones clave en la calidad de los datos son: completitud, existencia, consistencia, actitud y actualidad. Es importante profundizar en estos aspectos.
- Un ejemplo real sería una venta mal calculada por inconsistencia que puede llevar a decisiones empresariales incorrectas.
Limpieza y Transformación de Datos
Importancia de la Limpieza
- La limpieza implica corregir errores y preparar los datos para un análisis efectivo. Es una etapa esencial en ciencia de datos.
- Técnicas comunes incluyen eliminar duplicados, tratar valores faltantes y unificar formatos.
Transformación y Feature Engineering
- La transformación consiste en convertir los datos para hacerlos más útiles tanto para el análisis como para el modelado del negocio.
- El feature engineering se enfoca en crear nuevas variables que aporten valor al modelo analítico.
Errores Comunes y Conclusiones
Preparación antes del Análisis
- Aproximadamente el 80% del trabajo consiste en preparar los datos. Es vital limpiar y entender bien los datos antes del análisis.
- Los errores más comunes incluyen analizar sin limpiar, ignorar nulos o no validar duplicados; todos ellos pueden resultar costosos.
Introducción a la Unidad Tres: Análisis Exploratorio
Análisis Exploratorio (EDA)
- El EDA es el proceso inicial para explorar un dataset con el fin de entender su estructura antes del análisis profundo.
- Objetivos clave del EDA incluyen detectar patrones, identificar problemas y generar hipótesis sobre los datos.
Herramientas Utilizadas
- Se utilizan herramientas como tablas, gráficos estadísticos (univariados y bivariados). Estas ayudan a visualizar relaciones entre variables.
Análisis de Datos y Estadística en E-commerce
Herramientas de Análisis
- Se mencionan herramientas como histogramas, box plots, scatter plots y gráficos de barras como las más utilizadas para analizar datos de ventas.
- Un ejemplo práctico es detectar los productos más vendidos y analizar variaciones por fecha o ciudad.
Introducción a la Estadística
- La estadística se abordará en el curso, comenzando con una introducción que será profundizada posteriormente.
- La importancia de la estadística radica en que los datos en bruto son difíciles de interpretar; la estadística ayuda a simplificar este proceso.
Funciones de la Estadística
- La estadística permite recolectar, organizar, analizar e interpretar datos para mejorar la toma de decisiones.
- Se diferencia entre estadística descriptiva (qué pasó) e inferencial (qué podría pasar).
Ejemplos Prácticos
- En un e-commerce, ejemplos de estadística descriptiva incluyen promedios de compra y ventas diarias; mientras que la inferencial puede predecir comportamientos futuros.
Conceptos Clave en Estadística
- Definiciones importantes:
- Población: Todos los datos posibles (ej. todos los clientes).
- Muestra: Conjunto representativo (ej. 100 clientes).
- Variables: Características a medir (ej. edad, precio).
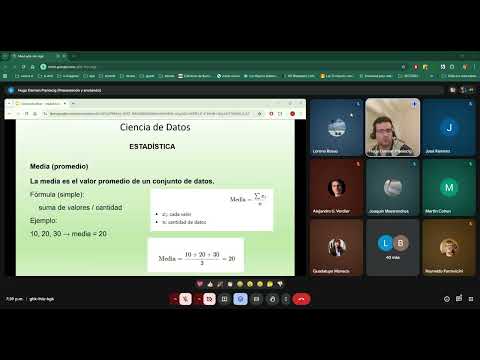
Medidas Centrales
- La media es el promedio; su cálculo puede ser engañoso si hay valores extremos (outliers).
- La mediana es el valor central al ordenar los datos; menos afectada por outliers que la media.
Moda y Distribución
- La moda representa el valor más frecuente dentro del conjunto de datos.
- Se presenta un cuadro conceptual sobre cuándo utilizar cada medida central.
Importancia y Errores Comunes en Estadística
- La estadística es crucial para entender datos, validar resultados y construir modelos efectivos.
- Errores comunes incluyen usar promedios sin contexto o confundir correlación con causalidad.
Introducción a la Estadística y Probabilidad
Importancia de Elegir las Medidas Correctas
- No todas las medidas estadísticas cuentan la misma historia; es fundamental elegir la correcta para interpretar los datos adecuadamente.
- La estadística es esencial en la ciencia de datos, ya que permite entender el pasado, interpretar el presente y prepararse para el futuro.
Conceptos Básicos de Probabilidad
- La probabilidad mide qué tan posible es que ocurra un evento, cuantificando así la incertidumbre.
- Ejemplo clásico: al lanzar una moneda, hay un 50% de probabilidad de obtener cara o cruz.
- La escala de probabilidad va de 0 (imposible) a 1 (seguro), con ejemplos como la lluvia mañana (0.7) y ganar la lotería (0.001).
Aplicaciones Prácticas de la Probabilidad
- En e-commerce se utiliza para calcular probabilidades de compra; en salud, para determinar riesgos de enfermedades.
- Se hará un repaso sobre conceptos olvidados antes de profundizar más en estadística.
Introducción al Machine Learning
¿Qué es Machine Learning?
- Machine learning permite a las computadoras aprender patrones a partir de datos para hacer predicciones y clasificaciones.
- Es una rama de inteligencia artificial que enseña a las máquinas a reconocer patrones usando datos como fuente.
Proceso dentro de Ciencia de Datos
- En ciencia de datos, machine learning se aplica después del análisis descriptivo y diagnóstico, enfocándose en anticipar resultados futuros.
- Permite clasificar casos y detectar comportamientos mediante modelos predictivos.
Resolución de Problemas Complejos
- El análisis descriptivo explica qué pasó; el predictivo anticipa qué podría pasar. Machine learning aborda ambos tipos.
- Es útil cuando hay demasiados datos o complejidad para definir reglas manualmente, como en detección de fraudes.
Ejemplos Prácticos
- Machine learning ayuda a crear modelos que aprenden patrones previos sin necesidad de definir cada regla manualmente.
¿Cuál es la diferencia entre programación tradicional y machine learning?
Conceptos Básicos de Programación Tradicional y Machine Learning
- La programación tradicional implica dar reglas al sistema, donde se aplica un esquema de "datos más reglas igual a resultado".
- En machine learning, se utilizan datos históricos junto con resultados conocidos para que el sistema aprenda reglas implícitas y realice predicciones basadas en nuevos datos.
Tipos de Machine Learning
Aprendizaje Supervisado
- El aprendizaje supervisado se basa en ejemplos con respuestas conocidas. Se le proporciona al modelo casos resueltos para que pueda aprender a resolver nuevos casos.
- Ejemplo: Para predecir si un cliente comprará, se utilizan datos históricos como edad e ingresos, donde la columna "compra" ya está informada.
- Este tipo de aprendizaje tiene una variable objetivo que queremos predecir, permitiendo resolver problemas como predicción de ventas o detección de fraudes.
Subtipos del Aprendizaje Supervisado
- Dentro del aprendizaje supervisado hay dos subtipos: clasificación (respuestas categóricas como sí/no) y regresión (respuestas numéricas).
- Clasificación se utiliza para etiquetar categorías; regresión se usa para predecir valores numéricos.
Aprendizaje No Supervisado
- A diferencia del supervisado, en el no supervisado no conocemos la variable de respuesta. El objetivo es encontrar patrones ocultos en los datos.
- Ejemplo: Agrupación de clientes sin una etiqueta definida permite descubrir similitudes y segmentar mercados.
Comparación entre Aprendizaje Supervisado y No Supervisado
- En resumen, el aprendizaje supervisado busca predecir mientras que el no supervisado está enfocado en descubrir patrones ocultos.
Variables Clave en Machine Learning
Variables de Entrada (Features)
- Las variables de entrada son aquellas utilizadas para describir cada caso. Por ejemplo, edad e ingresos son características importantes al analizar clientes.
Variable Objetivo (Target)
- La variable objetivo es aquella que queremos predecir. Por ejemplo, determinar si un cliente realizará una compra o si hay fraude involucrado.
¿Cómo funciona el aprendizaje supervisado en modelos de predicción?
Introducción al Aprendizaje Supervisado
- Se discute la importancia de conocer las ventas del mes siguiente y los riesgos de abandono, destacando que el "target" o variable objetivo es esencial para el modelo.
- El "target" se define como el resultado conocido que utiliza el modelo para aprender, lo cual puede ser problemático en algunos casos.
Proceso de Entrenamiento del Modelo
- El entrenamiento implica analizar datos históricos para aprender patrones. Existen diversas técnicas que se explorarán a lo largo del curso.
- Un ejemplo práctico muestra cómo los clientes con más visitas tienden a comprar más, sugiriendo que el modelo busca reglas generales en los datos.
Predicción y Aplicación del Modelo
- La predicción es el resultado generado por el modelo al recibir un nuevo caso, como predecir si un cliente específico realizará una compra basándose en sus características.
- El modelo aprende del pasado para estimar comportamientos futuros, utilizando datos como ingresos y visitas a la web para hacer predicciones sobre nuevos usuarios.
Ciclo de Trabajo del Modelo
- Se describe un ciclo conceptual donde se reúnen datos históricos, se identifican variables relevantes y se entrena al modelo para encontrar patrones antes de aplicarlo a nuevos usuarios.
- La interpretación sugiere que aquellos con más visitas y mayores ingresos tienen mayor probabilidad de compra, resaltando la utilidad práctica del modelo.
Aplicaciones Prácticas y Requisitos del Modelo
- Ejemplos de aplicaciones incluyen e-commerce (recomendaciones), salud (predicción de enfermedades), finanzas (detección de fraudes), logística (predicción de demanda), entre otros.
- Para que un modelo funcione correctamente, necesita datos de calidad, suficientes ejemplos y variables relevantes; además debe tener un objetivo bien definido.
Limitaciones y Consideraciones Finales
- Si los datos son deficientes o irrelevantes, el rendimiento del modelo será pobre. Es crucial definir claramente qué queremos predecir para diseñar adecuadamente el problema.
- Los modelos pueden presentar sesgos si los datos históricos también los tienen. Además, no reemplazan la decisión humana; son herramientas que ayudan en la toma de decisiones informadas.