Clase01a 02
Análisis Detallado del Video
Resumen de la Sección: En esta sección, se discute la complejidad de los modelos neuronales en relación con la cantidad de neuronas necesarias para una buena clasificación y cómo aumentar las capas puede ayudar a simplificar el problema.
Complejidad del Modelo y Cantidad de Neuronas
- Se requieren al menos cuatro neuronas para una buena clasificación en un problema complejo.
- A medida que aumenta la complejidad del modelo, se necesitan más neuronas en la capa oculta para reducir errores.
- Agregar más rectas (neuronas) puede llevar al sobreajuste del modelo.
Transformación del Espacio
- La transformación del espacio con 10 neuronas genera un espacio de 10 dimensiones con 26 regiones separadas.
- En un espacio de 10 dimensiones, se forman 26 clústeres separados que requieren nuevas rectas para su separación.
Añadiendo Capas al Modelo
- Al agregar más capas, se realizan más transformaciones entre espacios n-dimensionales, buscando simplificar el problema en cada etapa.
- El objetivo es que cada capa simplifique progresivamente el problema hasta que la capa final logre una buena separación para una clasificación precisa.
Resultados Empíricos vs. Pruebas Teóricas
- Los resultados empíricos respaldan el uso de arquitecturas profundas en redes neuronales, aunque no hay pruebas teóricas definitivas sobre su eficacia.
- Aunque los resultados experimentales son positivos, aún falta una prueba analítica sólida sobre la efectividad de añadir más capas a los modelos.
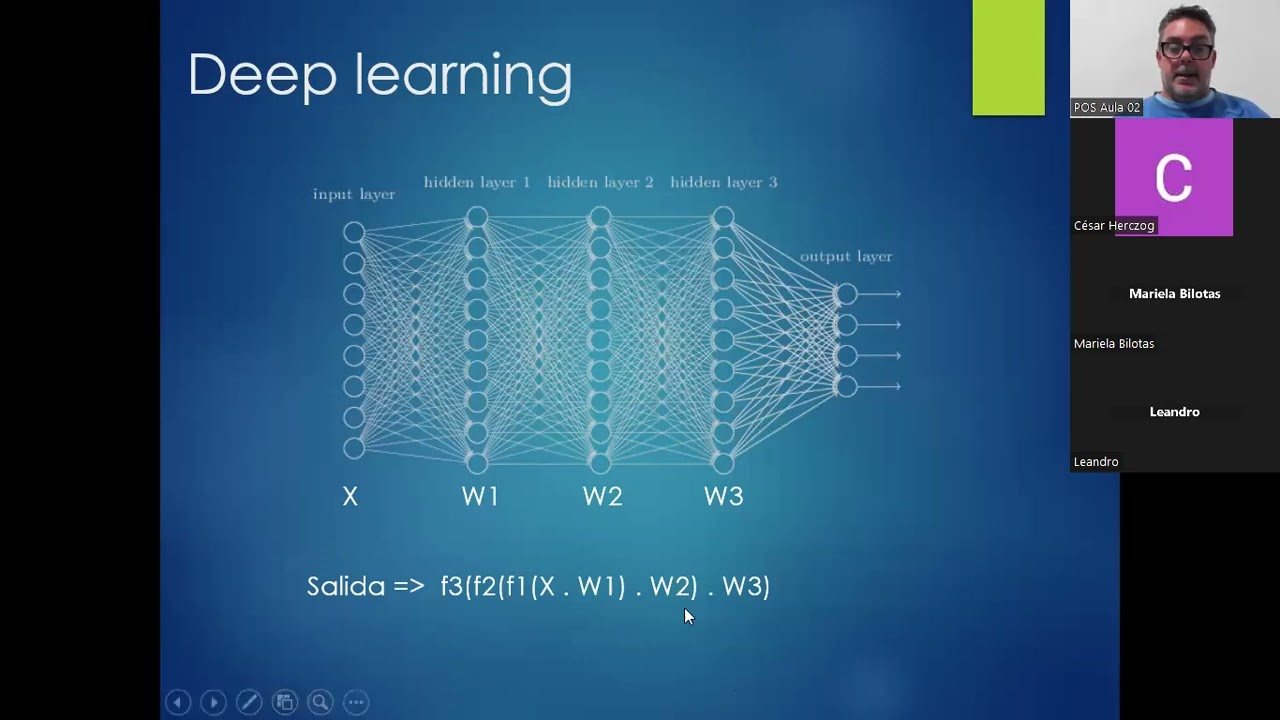
Funcionamiento y Estructura Profunda
Análisis Detallado de Redes Neuronales
Resumen de la Sección: En esta sección, se profundiza en el cálculo del error en redes neuronales, la importancia de la linealidad en las funciones aplicadas, y cómo la elección de capas y neuronas impacta en la resolución de problemas.
Cálculo del Error y Complejidad Matemática
- Se explica cómo se calcula el error de una red neuronal mediante diferencias cuadráticas y medias.
- Se destaca que aunque las operaciones pueden volverse complejas, siguen siendo efectivas.
Linealidad y Funciones Aplicadas
- Se menciona que todas las multiplicaciones en realidad son operaciones con matrices y vectores.
- La adición de capas no aporta si se usan funciones lineales; romper la linealidad es clave para resolver problemas.
Arquitectura y Topologías
- Las capas en una red neuronal pueden considerarse como una representación del cálculo del error.
- Se exploran topologías acíclicas y cíclicas que permiten mayor flexibilidad en el diseño de redes neuronales.
Elección de Capas y Neuronas
- La decisión sobre cuántas capas y neuronas incluir se vuelve crucial para encontrar la arquitectura óptima.
- No existe un manual definitivo; cada problema requiere su propia arquitectura a través de prueba y error.
Entrenamiento y Descenso del Gradiente
- El proceso de entrenamiento implica establecer una arquitectura inicial seguido por el algoritmo backpropagation.
- Se ajusta continuamente la arquitectura probando diferentes configuraciones hasta encontrar la más adecuada.
Descenso del Gradiente
- Para minimizar el error, se desciende sobre una superficie desconocida utilizando gradientes negativos.
Explicación detallada sobre el entrenamiento de redes neuronales
Resumen de la sección: En esta parte, se profundiza en el proceso de entrenamiento de redes neuronales, abordando temas como el cálculo del gradiente, la importancia de la inicialización de los pesos y la velocidad de aprendizaje.
Cálculo del gradiente y movimiento hacia mínimos locales
- Se explica que al calcular el gradiente de una función, este siempre será distinto de cero, lo que lleva a movimientos incrementales hacia mínimos locales.
- La elección de la inicialización de los pesos puede determinar si se cae en un mínimo local o global durante el descenso aritmético.
Importancia de la inicialización y variabilidad
- La variabilidad en la inicialización de los pesos puede llevar a diferentes resultados en una misma arquitectura neuronal.
- Se destaca la necesidad de probar múltiples inicializaciones para encontrar un mejor resultado.
Velocidad de aprendizaje y convergencia
- La velocidad de aprendizaje (Alfa) influye en el tamaño del paso dado en cada iteración, afectando directamente la convergencia hacia un mínimo.
- Un Alfa inadecuado puede provocar divergencia o convergencia lenta del modelo durante el entrenamiento.
Monitoreo y ajuste durante el entrenamiento
- Es crucial monitorear constantemente parámetros como el error durante el entrenamiento para ajustar hiperparámetros como Alfa.
- Observar cómo disminuye el error a lo largo del tiempo es fundamental para identificar si se está alcanzando un mínimo global o local.
Optimización del modelo y evaluación
Resumen de la sección: En esta parte, se aborda cómo optimizar un modelo neuronal mediante ajustes continuos y evaluaciones precisas.
Identificación y corrección ante estancamientos
- Ante estancamientos en la reducción del error durante el entrenamiento, es necesario considerar cambios en arquitectura o hiperparámetros.
Ajustes según desempeño y errores
- El análisis detallado del comportamiento del error puede sugerir modificaciones en hiperparámetros como Alfa para mejorar resultados.
Evaluación con conjuntos separados
Explicación del Proceso de Actualización de Pesos en Redes Neuronales
Resumen de la Sección: En esta sección, se detalla el proceso de actualización de pesos en redes neuronales, explicando cómo se modifican los pesos de las neuronas en función del error cometido y la velocidad de aprendizaje.
Proceso de Propagación y Etapa Back
- La actualización de los pesos en las neuronas se realiza a través del Alfa, que representa la velocidad de aprendizaje y el error cometido por las neuronas de la capa siguiente.
- La etapa "back" implica retroceder desde la última capa hacia la primera, transfiriendo el error entre capas para actualizar los pesos.
Cálculo del Error y Actualización Iterativa
- Se calcula el error en cada muestra del dataset, derivando todas sus variables para ajustar los pesos.
- El problema radica en calcular derivadas con una sola muestra, lo que genera superficies engañosas al actualizar los pesos.
Desafíos del Descenso del Gradiente en Redes Neuronales
Resumen de la Sección: Aquí se abordan los desafíos asociados al descenso del gradiente en redes neuronales debido a cálculos basados en muestras individuales que generan inestabilidad.
Cambios Constantes y Superficies Engañosas
- Los cálculos con muestras individuales generan cambios constantes en las superficies de error, dificultando el descenso efectivo.
- La analogía con cambiar constantemente entre planetas ilustra cómo estos cambios afectan la dirección del descenso.
Impacto en Iteraciones y Épocas
- Cada muestra requiere cálculos distintos, generando iteraciones únicas que impactan el proceso iterativo completo.
- Trabajar con múltiples muestras permite construir una superficie más precisa pero aumenta significativamente la complejidad computacional.
Optimización Mediante Descenso Estocástico del Gradiente
Resumen de la Sección: Se explora cómo el descenso estocástico puede acercarse al mínimo real a pesar de mínimos locales mediante estrategias híbridas.
Estrategias Híbridas y Superficies Parciales
- El uso combinado de superficies parciales con un número limitado de muestras permite aproximarse al mínimo real eficientemente.
- Ajustar hiperparámetros como B (cantidad de muestras por lote) influye en si se trabaja muestra a muestra o con lotes completos para optimizar el proceso.
Mínimos Locales y Redes Neuronales
Resumen de la Sección: En esta sección, se discute la noción de mínimos locales en el contexto de superficies de error y cómo afectan a los procesos de optimización. Además, se aborda la importancia del reordenamiento de lotes en el entrenamiento de redes neuronales.
Mínimos Locales
- Los mínimos locales son puntos donde el valor de una función es menor que en sus alrededores.
- Al descender por una superficie de error, es crucial identificar tanto los mínimos locales como el mínimo global para lograr un óptimo rendimiento.
- Saltar entre diferentes superficies puede ayudar a evitar quedar atrapado en mínimos locales subóptimos durante el proceso de optimización.
Entrenamiento con Lotes
- Las épocas representan iteraciones completas sobre todo el conjunto de datos, mientras que los lotes implican muestras más pequeñas utilizadas para actualizar los pesos en cada paso.
- Modificar el tamaño o reordenar los lotes puede influir en la cantidad y eficacia de las actualizaciones ponderadas durante el entrenamiento.
Desafíos y Estrategias en Redes Neuronales
Resumen de la Sección: Aquí se exploran desafíos comunes asociados con las redes neuronales, como encontrar arquitecturas adecuadas y evitar sobreajuste, junto con estrategias para mejorar su rendimiento.
Desafíos en Redes Neuronales
- La complejidad radica en hallar la arquitectura óptima que evite el sobreajuste sin comprometer la capacidad predictiva del modelo.
- La capacidad de aprendizaje está determinada por factores como la organización neuronal y los valores iniciales de los parámetros, lo que influye significativamente en alcanzar mínimos globales efectivos.
Estrategias para Mejorar Rendimiento
- La técnica del reordenamiento aleatorio de lotes puede ser beneficiosa para explorar nuevas superficies y evitar estancarse en mínimos locales subóptimos.
Aprendizaje por Error y Factor de Inercia
Resumen de la Sección: En esta sección, se discute el concepto de aprendizaje por error y la introducción del factor de inercia en el proceso.
Aprendizaje por Error
- El factor de inercia se agrega al proceso de aprendizaje por error para permitir escapar de mínimos locales.
- La velocidad de aprendizaje se ve influenciada por factores como el error, la entrada y el término anterior.
Factor de Inercia
- El factor de inercia brinda la oportunidad de evitar quedar atrapado en mínimos locales.
- Dependiendo del valor del factor alfa, se puede salir eficazmente de ciertos mínimos locales.
Funciones Derivables y Trampas Matemáticas
Resumen de la Sección: Aquí se aborda la derivabilidad en las funciones de activación, centrándose en casos específicos como ReLU.
Funciones Derivables
- Aunque ReLU no es derivable en cero, se pueden aplicar trampas matemáticas para calcular su derivada.
- La estrategia consiste en considerar dos funciones (recta horizontal y compendi 45) para obtener una derivada válida.
Entrenamiento por Lotes y Superficie del Error
Resumen de la Sección: Se explora cómo funciona el entrenamiento por lotes y su relación con la superficie del error.
Entrenamiento por Lotes
- En el entrenamiento por lotes, cada lote presenta n muestras que contribuyen a calcular un único punto en la superficie del error.
Análisis Detallado de la Conversación
Regresión Múltiple y Redes Generativas
Descripción de la Sección: En esta sección, se discute el concepto de regresión múltiple y su relación con las redes generativas.
- La regresión múltiple implica muchas entradas que generan muchas salidas.
- En el contexto de generación de imágenes, se ilustra cómo a partir de tres variables de entrada se pueden generar 10,000 píxeles como salida.
- Las redes generativas producen mucha salida a partir de poca entrada, como en el caso del modelo GPT que genera contenido extenso a partir de un prompt corto.
Clasificación y Arquitectura Neuronal
Descripción de la Sección: Aquí se aborda la clasificación y la arquitectura neuronal necesaria para tareas específicas.
- En clasificación, las capas ocultas trazan límites para separar clases; cuantas más neuronas en la capa oculta, más complejo el modelo.
- Para problemas simples, una neurona puede ser suficiente en la capa de salida; sin embargo, para tareas más complejas, puede requerirse un modelo por cada variable.
- Una solución es entrenar tantos modelos como variables de salida; por ejemplo, en un caso con cuatro variables distintas se entrenarían cuatro modelos independientes.
Arquitectura y Funciones de Activación
Descripción de la Sección: Se profundiza en aspectos clave relacionados con la arquitectura neuronal y las funciones de activación.
- La elección entre varios modelos o uno único depende del contexto; para clasificación se suele usar una neurona por clase en la capa de salida.
- La cantidad de neuronas en la capa final depende del problema; por ejemplo, para imágenes podría haber tantas neuronas como píxeles a predecir.
- En clasificación multiclase, se emplea codificación one-hot donde cada neurona representa una clase distinta.
Entrenamiento y Resultados
Descripción de la Sección: Aquí se discute cómo los resultados finales están influenciados por el proceso de entrenamiento y las decisiones arquitectónicas.
- El éxito del entrenamiento está ligado a decisiones sobre capas ocultas y neuronas; adaptar estas estructuras es crucial para obtener buenos resultados.
- En clasificación multiclase, una neurona por clase simplifica el proceso al indicar directamente qué clase corresponde cada salida esperada.
Funciones Lineales vs. Funciones no Lineales
Descripción de la Sección: Se explora cómo las funciones lineales y no lineales afectan los resultados finales en redes neuronales.
- La elección entre funciones lineales o no lineales impacta en si los valores resultantes son acotados o no; esto influye directamente en interpretaciones correctas.
- Para asegurar interpretaciones claras en clasificaciones multiclase, es fundamental utilizar funciones adecuadas que limiten los valores obtenidos.
Interpretación Correcta y Problemas Potenciales
Descripción de la Sección: Finalmente, se abordan cuestiones sobre interpretación correcta y posibles desafíos al trabajar con redes neuronales.
- Valores inadecuados al redondear salidas pueden llevar a malinterpretaciones o falta de precisión en las predicciones finales.
Redondeo Matemático y Capa Softmax
Resumen de la Sección: En esta sección, se discute el redondeo matemático y la utilización de la capa softmax en redes neuronales para interpretar probabilidades.
Redondeo Matemático
- El redondeo matemático puede afectar las respuestas de una red neuronal, mostrando sensibilidad a pequeñas variaciones.
- Es crucial verificar los valores de salida y no confiar ciegamente en la red, considerando posibles diferencias significativas por mínimas variaciones decimales.
Capa Softmax
- La capa softmax se utiliza para convertir valores en una distribución de probabilidad, facilitando interpretar salidas inciertas como probabilidades claras.
- Al aplicar la capa softmax a valores redondeados, se obtienen probabilidades normalizadas que suman uno, brindando mayor certeza en las predicciones.
Entropía Cruzada y Cálculo del Error
Resumen de la Sección: Aquí se explora el concepto de entropía cruzada como método para calcular errores en redes neuronales.
Entropía Cruzada
- La entropía cruzada permite interpretar errores basados en las salidas reales esperadas, asignando altos errores a predicciones incorrectas.
- A diferencia del error cuadrático medio, la entropía cruzada busca minimizar los mínimos locales en la función de error, ofreciendo resultados más precisos en problemas complejos.
Cálculo del Error
- El cálculo del error mediante logaritmos ayuda a determinar discrepancias entre las salidas reales y las predichas por la red neuronal.
Resumen Detallado
Entendiendo la Entropía Cruzada y Redes Neuronales Artificiales
Resumen de la Sección: En esta sección, se aborda el concepto de entropía cruzada en el contexto del cálculo del error en redes neuronales artificiales. Además, se discute la importancia de contar con un dataset etiquetado para trabajar con este tipo de redes y se detalla el proceso de configuración de una red neuronal artificial.
- El error en la salida esperada es alto cuando hay una discrepancia significativa entre el valor esperado y el obtenido.
- La entropía cruzada permite calcular errores mínimos cuando las salidas esperadas y reales coinciden.
- Para trabajar con redes neuronales artificiales, es fundamental disponer de un dataset etiquetado para clasificación o regresión.
- La configuración de una red neuronal implica establecer pesos iniciales, hiperparámetros como la velocidad de aprendizaje y definir la arquitectura con capas y neuronas.
- El algoritmo clásico para optimizar los pesos en una red neuronal es el backpropagation, que utiliza métodos como el descenso por gradiente negativo.
Preparación y Uso Práctico de Modelos Predictivos
Resumen de la Sección: En esta parte, se explora cómo construir modelos predictivos utilizando redes neuronales artificiales, desde la elección inicial de pesos hasta la presentación de nuevas muestras al modelo entrenado.
- Trabajar con redes neuronales requiere no solo un dataset etiquetado sino también un algoritmo de aprendizaje, métricas de error y una configuración adecuada.
- Una vez optimizados los pesos del modelo a través del error seleccionado, este está listo para predecir respuestas ante nuevas muestras.
Repaso y Perspectivas Futuras sobre Redes Convolucionales
Resumen de la Sección: Aquí se menciona un repaso futuro sobre redes convolucionales como continuación del tema tratado previamente en clases anteriores.
- Se plantea realizar un repaso sobre redes convolucionales en la próxima clase presencial para profundizar en temas pendientes.
- Se destaca la importancia del repaso debido a posibles diferencias en conocimientos previos sobre aprendizaje automático entre los estudiantes.
Reflexiones Finales y Expectativas
Resumen Final: Las reflexiones finales abordan las expectativas respecto a lo visto hasta ahora y plantean posibles ampliaciones temáticas según las necesidades e intereses del grupo.
- Se invita a los estudiantes a evaluar su comprensión actual sobre los temas vistos hasta ahora para orientar futuras discusiones.
Resumen Detallado
Convocatoria a la Clase y Materiales Disponibles
- Se menciona que se verá un hiper resumen de las redes neuronales convolucionales al día siguiente.
- Se pregunta si las clases compactas anteriores están grabadas en algún lugar para revisar con más detalle.
- Se indica que es posible que existan grabaciones de años anteriores, y se ofrece buscarlas si hay interés.
Profundidad del Contenido y Evaluación
- Se aclara que el curso no se centrará en cálculos matemáticos complejos como Back Propagation o multiplicación de matrices, sino en comprender conceptos clave.
- Se confirma la hora de la próxima clase y se detalla que el examen será abierto libro, permitiendo el uso de todo el material compartido durante el curso.
- El examen consistirá en preguntas teóricas sin requerir codificación, abarcando tanto teoría como práctica vista durante las clases.
Exámenes y Trabajos Prácticos
- Se asegura que los exámenes no serán complicados ni destructivos, animando a consultar con compañeros de años anteriores para mayor claridad sobre su formato.