Clase01a 02
New Section
In this section, the speaker discusses the complexity of neural networks and the relationship between the number of neurons and model performance.
Neural Network Complexity
- The speaker mentions that for a problem with two classes, at least four neurons are needed for a good classification.
- As the complexity of data topology increases, more neurons in hidden layers are required to improve classification accuracy.
- Adding more neurons (representing more lines) can lead to overfitting, where the model fits too closely to the training data.
- Increasing neuron count results in higher-dimensional spaces for transformations, impacting separation capabilities.
- With 10 neurons separating data into 26 regions in a 10-dimensional space, clusters form for classification.
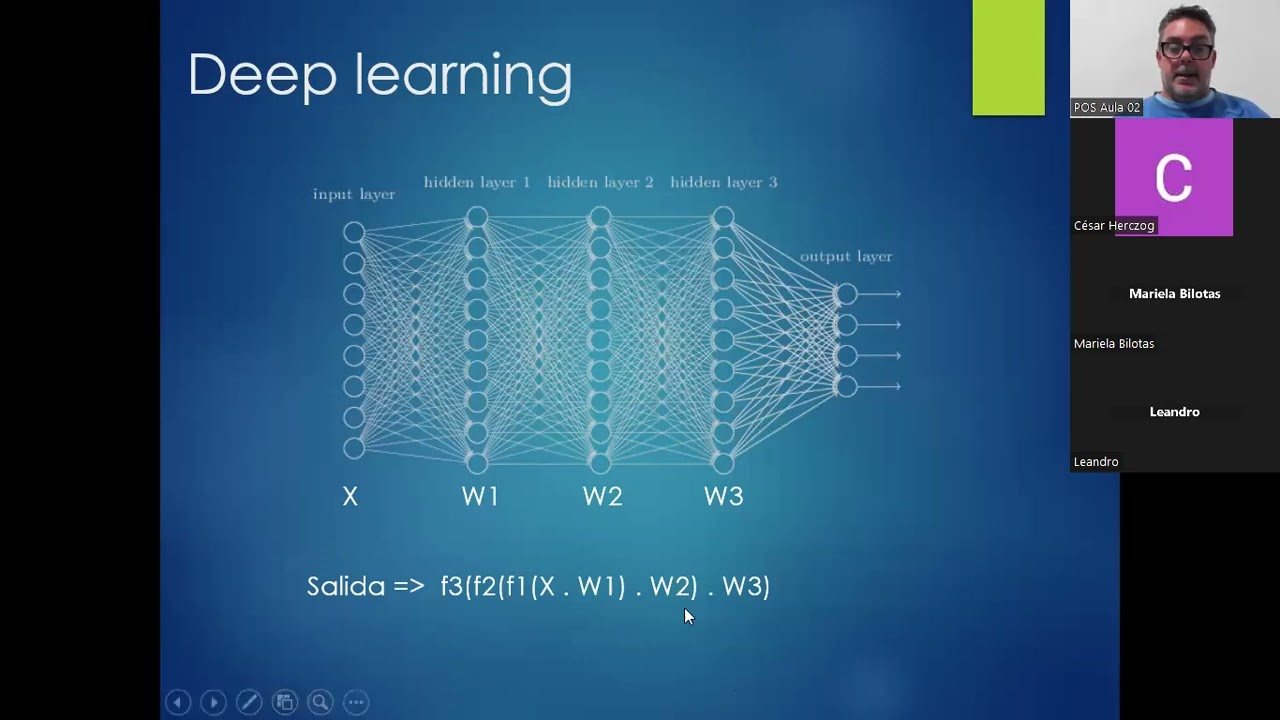
Neural Network Layers and Transformations
This part delves into how adding layers in neural networks aids in simplifying complex problems through successive transformations.
Layered Transformations
- Introducing multiple layers involves transforming data successively to simplify separations between classes.
- Each layer adds new dimensions to transform data further, aiming to enhance separability and simplify tasks gradually.
- The objective of adding layers is to iteratively simplify problems by improving class separations at each stage.
- The goal is for each layer to refine separations so that the final layer achieves accurate classification efficiently.
Empirical Results vs. Theoretical Understanding
This segment contrasts empirical evidence supporting deep architectures with theoretical challenges in understanding their workings.
Empirical vs. Theoretical Support
- Empirical results demonstrate the effectiveness of deep architectures despite lacking strong theoretical backing.
- Deep learning often relies on trial-and-error due to complex mathematical underpinnings not fully understood theoretically.
- Varying neuron counts per layer allow continuous transformation from an n-dimensional space to an m-dimensional one for improved separability.
Functionality and Mathematical Complexity
Exploring current trends in deep learning models and their practical application despite underlying mathematical intricacies.
Practical Application
- Deep learning's popularity stems from its practical success despite lacking comprehensive analytical proofs of functionality.
Understanding Neural Network Mathematics
In this section, the speaker delves into the mathematical complexities of neural networks, focusing on error calculation and network structure.
Mathematical Complexity of Neural Networks
- The process involves calculating the quadratic difference between the actual and expected outputs to determine the network's error.
- Linearity is crucial in neural networks, with functions like X by W applied. Non-linear functions can break this linearity.
- Expressions in neural networks can be represented as matrix and vector multiplications, simplifying complex calculations.
Importance of Network Architecture
- Adding layers to a neural network doesn't enhance performance unless non-linear transfer functions are introduced to break linearity.
- Each layer in a network can be viewed as a computational unit, aiding in error calculation and training efficiency.
Exploring Network Topologies
This segment discusses different network topologies beyond linear structures, introducing acyclic and cyclic architectures for enhanced flexibility.
Linear vs. Non-linear Topologies
- Acyclic topologies transform networks into graphs allowing for multiple inputs, bifurcations, and convergences.
Architectural Decision Making
- Choosing the number of layers and neurons becomes more intricate with non-linear topologies, requiring trial-and-error exploration for optimal architecture design.
Training Neural Networks
The speaker elaborates on the training process of neural networks, emphasizing architecture establishment and gradient descent optimization.
Training Process Insights
- Regardless of architecture complexity, effective training relies on algorithms like backpropagation for error minimization.
Architectural Optimization
- Iterative adjustments to network architecture involve adding or removing layers/neurons while fine-tuning hyperparameters for optimal model fit.
Gradient Descent Technique
Detailed explanation of gradient descent technique used in optimizing neural networks through iterative parameter adjustments.
Descending Error Surfaces
- Gradient descent involves navigating error surfaces by iteratively adjusting parameters towards minimal error points.
Calculating Gradients
Calculating Gradients and Optimization in Neural Networks
In this section, the speaker discusses the calculation of gradients in functions and how it impacts movement towards minima in neural network optimization.
Calculating Gradients
- The gradient of a function is always non-zero, leading to incremental movements towards minima but never reaching the absolute minimum.
- Initialization of weights plays a crucial role in determining whether the model converges to a local or global minimum.
Impact of Initialization on Model Success
- Varying weight initialization can result in different outcomes for the same architecture and dataset.
- Experimenting with multiple initializations provides flexibility and can lead to improved model performance.
Importance of Learning Rate (Alpha) in Optimization
- The learning rate determines the size of steps taken during optimization.
- Choosing an appropriate learning rate is critical; too small leads to slow convergence, while too large may cause divergence.
Monitoring Training Progress
- Tracking error reduction during training helps assess model performance and convergence.
- Observing error trends guides adjustments such as modifying hyperparameters like learning rate for optimal results.
Model Evaluation and Overfitting
This segment delves into evaluating models through training and testing sets, addressing overfitting concerns.
Evaluating Model Performance
- Utilizing separate training and testing datasets aids in assessing model generalization capabilities effectively.
- Overfitting occurs when a model performs well on training data but poorly on unseen test data due to excessive complexity.
Error Analysis and Metric Selection
- Monitoring error levels post-training is essential; however, understanding acceptable error thresholds varies based on specific problems.
- For classification tasks, metrics like accuracy or precision are crucial for evaluating model efficacy beyond basic error calculations.
Understanding Neural Network Training Process
In this section, the speaker explains the process of updating weights in neural networks based on error and learning rate.
Weights Update Process
- The weights of neurons are updated based on the learning rate (Alpha) and the error committed by the neurons in the next layer. This process is known as forward propagation.
- Backpropagation involves transferring errors backward from the last to the first layer, updating weights based on Alpha and errors from the next layer's neurons.
Iterative Weight Adjustment
- For each neuron in each layer, errors are calculated, derivatives are computed, and weights are adjusted iteratively for each sample in a dataset.
- Calculating derivatives with a single sample leads to inaccurate error surfaces, causing fluctuations in weight updates akin to moving between different planets.
Importance of Dataset Size
- Working with multiple samples helps construct a more accurate error surface, aiding smoother descent towards minima but becomes computationally intensive for large datasets.
- Utilizing all dataset samples builds an exact error surface at each point, ensuring consistent descent towards minima without fluctuation between surfaces.
Optimizing Gradient Descent Strategies
This part delves into different gradient descent strategies and their impact on approaching minima efficiently.
Gradient Descent Strategies
- Stochastic gradient descent involves updating weights sample by sample, leading to fluctuating surfaces but eventually reaching a nearby minimum.
- While stochastic gradient descent may encounter local minima, it tends to converge close to true minima over iterations due to continuous adjustments.
Partial Surface Calculation
- Calculating partial surfaces using subsets of samples can provide a compromise between accuracy and computational efficiency compared to full dataset calculations.
- The stochastic gradient descent introduces a new hyperparameter 'B' representing batch size; B = 1 implies working sample by sample while B = n indicates classic full surface construction approach.
New Section
In this section, the speaker discusses the concept of local minima in optimization problems and how to navigate them effectively.
Local Minima in Optimization
- Local minima are points where the function has a lower value than its immediate surroundings.
- Transitioning between local minima can be achieved by changing parameters or surfaces in optimization processes.
- Moving between different surfaces can help avoid getting stuck in local minima, enhancing optimization success rates.
Optimization Techniques
The speaker elaborates on optimization techniques such as epochs, batches, and iterations in machine learning models.
Optimization Techniques
- Explanation of epochs (passing all dataset samples), batches (subset of data for calculations), and iterations (updating weights).
- Altering batch sizes affects the number of weight updates and optimization efficiency.
Challenges in Neural Networks
This part delves into challenges faced in neural networks, emphasizing architecture selection and parameter initialization importance.
Challenges Faced
- Difficulty lies in finding suitable network architectures to prevent overfitting.
- Learning capacity depends on neuron quantity and organization within layers.
Overfitting Concerns
The discussion centers around overfitting issues due to excessive complexity in neural networks.
Overfitting Analysis
- Overfitting risks increase with more complex models that fit training data too closely.
New Section
In this section, the speaker discusses the concept of inertia in learning speed and its impact on navigating local minima in optimization algorithms.
Understanding Inertia in Learning Speed
- The introduction of a new term, "inertia factor," influences learning speed by allowing escape from local minima.
- The ability to escape local minima depends on the steepness of the terrain and the value of the inertia factor.
- Proper adjustment of parameters like inertia factor and learning rate facilitates escaping certain local minima.
New Section
This part involves a brief discussion about taking a break before continuing with more content.
Break Discussion
- A suggestion for a 10-minute break is made to refresh before delving into further discussions.
- Questions or discussions are welcomed during the break time if needed.
New Section
Here, there is an explanation regarding activation functions and their derivability, focusing on ReLU as an example.
Activation Function Derivability
- Addressing concerns about ReLU's non-differentiability at zero but explaining how it can be managed using piecewise functions.
- Detailing how ReLU can be represented as two differentiable functions to ensure overall differentiability.
- Emphasizing that while ReLU may not be differentiable at specific points, it remains differentiable overall through careful handling.
New Section
This segment explores batch training processes and error calculation within neural networks.
Batch Training and Error Calculation
- Clarification on error calculation in batch training where errors are computed based on multiple samples but evaluated at individual points.
- Explanation that error calculations are consistent across samples within a batch due to utilizing the same weights for each sample presentation.
New Section
This part delves into error calculation specifics within neural networks during training processes.
Error Calculation Details
Understanding Neural Networks and Architectures
In this section, the speaker delves into the concept of multiple regression in neural networks, emphasizing the relationship between input and output variables in various scenarios.
Multiple Regression in Neural Networks
- Multiple regression involves numerous inputs leading to multiple outputs.
- Generating images exemplifies this concept, where each pixel contributes to the overall output image.
- Generative networks produce extensive outputs from minimal inputs, as seen in GPT chat models.
Neural Network Architecture for Classification
The discussion shifts towards neural network architectures for classification tasks, focusing on hidden layers and neuron allocation.
Hidden Layers and Neuron Allocation
- Hidden layers segment data into distinct regions using linear separations.
- Determining the number of neurons at the output layer depends on the task complexity.
Model Training Strategies for Varied Outputs
The speaker elaborates on training strategies based on output variability and model complexity.
Training Approaches for Varied Outputs
- Training individual models per output variable enhances performance but demands more resources.
- Tailoring models to specific variables optimizes outcomes, especially with diverse outputs like text or images.
Output Layer Design for Different Tasks
The focus is on designing the output layer based on task requirements such as image generation or classification.
Output Layer Design Considerations
- The number of neurons in the output layer aligns with task-specific needs (e.g., pixels in an image or classes in classification).
Activation Functions and Model Interpretation
Activation functions play a crucial role in model interpretation and performance evaluation.
Activation Functions Impact
Redondeo Matemático y Sensibilidad de la Red Neuronal
In this section, the speaker discusses the mathematical rounding and sensitivity of neural networks, emphasizing the importance of understanding output values and the impact of rounding on results.
Redondeo Matemático y Sensibilidad
- Mathematical rounding can lead to valid answers, but checking output values is crucial due to sensitivity in neural networks.
- Differences as small as a decimal point can significantly alter network responses, highlighting the need to verify and assess confidence in results.
- Utilizing softmax layers helps create a probability distribution from neuron values, aiding in uncertainty reduction and enhancing result interpretation.
- Softmax layer transforms neuron values into probabilities, facilitating clearer interpretations through probability distributions that sum up to one.
- Softmax layer assigns probabilities to potential outcomes based on neuron values, aiding in decision-making by providing clearer insights into possible results.
Error Calculation Methods: Mean Squared Error vs. Cross Entropy
This section delves into error calculation methods within neural networks, comparing mean squared error with cross entropy and their implications for model optimization.
Error Calculation Methods
- Mean squared error's convexity varies based on network complexity, potentially leading to multiple local minima instead of a global minimum.
- Cross entropy offers a convex error calculation method for most problems, aiming to minimize local minima presence for improved optimization.
- Cross entropy minimizes local minima occurrences within error surfaces by focusing on logarithmic calculations of neuron responses.
- Calculating errors using cross entropy involves logarithmic functions applied to expected outputs, influencing error rates based on predicted versus actual outcomes.
Entropy Crossed: Enhancing Error Surfaces for Neural Networks
The discussion shifts towards how cross entropy enhances error surfaces in neural networks by altering calculation methods and minimizing local minima presence.
Entropy Enhancement
- Cross entropy modifies error calculations by adjusting log functions based on expected versus actual outputs, impacting error rates accordingly.
New Section
In this section, the speaker discusses the importance of error analysis in neural networks and the significance of labeled datasets for artificial neural network training.
Error Analysis and Labeled Datasets
- The speaker highlights a significant error in the output, emphasizing the need for accuracy in neural network predictions.
- Error analysis is crucial, with lower errors indicating better model performance. Expectations versus actual outputs are key in determining error rates.
- Labeled datasets are essential for training artificial neural networks, especially for classification and regression tasks.
- Configuring a neural network involves setting initial weights, hyperparameters like learning rate, layer quantities, and neuron counts per layer.
- Training algorithms like backpropagation optimize initial weights based on chosen error metrics such as mean squared error or cross-entropy.
Next Steps in Neural Network Training
This section delves into preparing neural networks for prediction tasks by optimizing models through training data and error metrics selection.
Model Optimization and Prediction
- After model optimization based on chosen error metrics, the trained model can be used to predict outcomes for new data samples.
- Successful neural network implementation requires not only labeled datasets but also appropriate learning algorithms, error metrics, and network configurations.
Upcoming Class Agenda
The speaker outlines the agenda for the upcoming class session focusing on convolutional neural networks (CNNs).
Agenda Preview
- The next class will include a review session due to the extensive content covered previously.
- Discussion on students' familiarity with machine learning topics to tailor future sessions accordingly.
Exploring Convolutional Neural Networks
This part introduces convolutional neural networks (CNNs), highlighting their relevance and practical applications in modern machine learning.
Understanding CNN Basics
- CNN exploration will cover newer concepts like CNN layers and practical exercises using Python libraries like TensorFlow or Colab.
- A brief overview of previous exposure to CNN topics among students is discussed to gauge familiarity levels before diving deeper into CNN concepts.
Depth of Previous Learning Experience
Assessing students' prior exposure to convolutional neural networks (CNN), reflecting on past educational experiences related to machine learning topics.
Evaluating Prior Knowledge
- Students' depth of understanding regarding CNN concepts from previous courses is considered to tailor upcoming lessons effectively.
- Reflecting on historical teaching methods related to CNN topics provides insights into potential gaps in knowledge among students.
Closing Remarks and Future Directions
Concluding thoughts on today's session while setting expectations for future classes focused on expanding upon current knowledge gaps.
Wrapping Up Today's Session
Convolutional Neural Networks and Course Logistics
In this section, the instructor discusses Convolutional Neural Networks (CNNs) and provides information about course logistics, including the availability of pre-prepared notebooks for practical use.
Understanding Convolutional Neural Networks
- CNNs will be covered in detail, with a hyper-summary planned for the following day.
Course Logistics and Practical Implementation
- Notebooks are available on campus for immediate use without requiring programming.
- Modifications such as adjusting neuron quantity or layer count can be made after understanding the provided material.
Course Content Availability and Exam Details
This part focuses on accessing course content, particularly recorded classes, and provides insights into the upcoming exam format.
Accessing Recorded Classes
- Enquiry about accessing previously recorded compact classes for detailed review.
Exam Format and Preparation Guidance
The instructor clarifies exam expectations, emphasizing conceptual understanding over mathematical calculations.
Exam Expectations
- The exam will not involve complex mathematical calculations like Backpropagation or matrix multiplication.
- Emphasis is placed on understanding concepts such as gradient calculation rather than manual computation.
Exam Structure and Evaluation Criteria
Details regarding the open-book exam structure, evaluation criteria, and emphasis on theoretical questions are discussed.
Open-Book Exam Structure
- The exam will be open-book with all necessary materials provided by the instructor.
Evaluation Criteria
- The exam will focus more on theoretical questions rather than coding tasks.
Practical Assignments Clarification
Addressing concerns about practical assignments and providing guidance on managing coursework effectively.
Practical Assignments Explanation
- Practical assignments serve to apply theoretical knowledge to real or simulated problems.
Closure and Next Steps
Concluding remarks regarding practical assignments and readiness for the upcoming session.
Final Remarks
- No formal practical assignments need to be submitted; practice is essential for reinforcing theoretical concepts.