Neo4j - Causal Cluster Introduction and Demo - NoSQL Databases #9
Cluster 개념 및 이점
섹션 개요: 클러스터란 무엇인가, 그리고 클러스터링의 장점에 대한 설명
클러스터란?
- 클러스터는 독립적인 서버들이 전용 네트워크를 통해 연결되어 구성된 그룹입니다.
- 다양한 서버들이 모여 하나의 클러스터를 형성합니다.
클러스터링의 장점
- 성능 향상: 다수의 노드로 인해 병렬 처리가 가능하여 성능이 향상됩니다.
- 데이터 가용성: 한 노드가 실패하더라도 다른 노드에서 데이터를 읽을 수 있으며, 데이터 중복성과 병렬 처리가 가능합니다.
Neo4j 내 Casual Cluster
섹션 개요: Neo4j에서 제공하는 Casual Cluster에 대한 설명
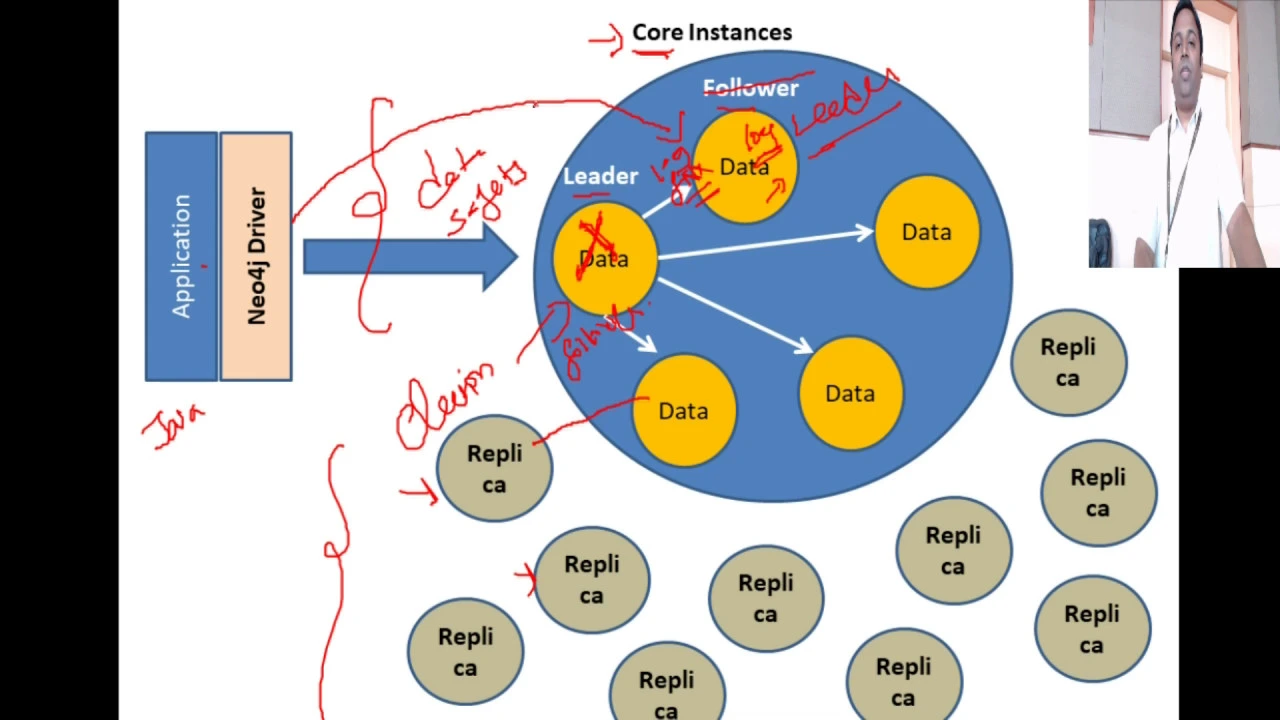
Core Server와 Replica Server
- Casual Cluster에는 Core Server와 Replica Server 두 가지 유형의 서버가 존재합니다.
- Core Server는 데이터 안전 및 오류 허용을 담당하는 리더와 팔로워로 분류됩니다.
Core Instance 및 Leader-Follower 모델
섹션 개요: Core Instance와 리더-팔로워 모델에 대한 상세 설명
Core Instance 및 리더-팔로워 역할
- Core Instance는 리더(Leader)와 팔로워(Follower) 역할을 수행하며, 어플리케이션이 Neo4j 드라이버를 사용할 때 데이터를 처리합니다.
- 리더는 어플리케이션으로부터 데이터를 받아 팔로워들에게 전달하며, 로그 파일을 통해 데이터 복제 및 조작이 이루어집니다.
리더 선출 및 자동화된 과정
섹션 개요: 리더 선출 과정과 자동화된 기능에 대한 이해
리더 선출 프로세스
- 리더 선출은 로그 유지 여부, 활동 기간 등 여러 요소에 따라 결정되며, 자동으로 진행됩니다.
- 일정 시간 후 현재 리더가 패배할 경우 새로운 리더가 선택되며, 데이터는 로그 파일을 통해 패롯들에게 전달됩니다.
Replica Server 및 핵심 차이점
섹션 개요: Replica Server의 역할과 핵심 차이점 설명
Replica Server와 Core Instance 비교
리더에게 데이터 전달
섹션 개요: 이 섹션에서는 트랜잭션이 어떻게 관리되는지, 리더가 언제 커밋을 발행하는지 등에 대해 설명합니다.
데이터 트랜잭션 관리
- 트랜잭션 단계가 팔로워들에게 전파됩니다.
- RAP 프로토콜은 왜 사용되는가?
- 클러스터 멤버십이 발생하면 새로운 노드가 가입하고 트랜잭션 커밋 및 리더 선출이 처리됩니다.
캐처 프로토콜
섹션 개요: 새로운 인스턴스에 데이터를 복사하는 방법과 중요성에 대해 다룹니다.
캐처 프로토콜 활용
- 노드 간 동기화를 위해 사용되며, 데이터 복사와 동기화를 담당합니다.
- 동기화 방법으로 '풀링'과 '직접 데이터베이스 코드 복사' 방식을 소개합니다.
노드 동기화 유지 방법
섹션 개요: 노드의 동기화 유지를 위한 방법과 중요성을 다루며, '풀링'과 '직접 데이터베이스 코드 복사'의 차이를 설명합니다.
노드 동기화 유지
- '풀링' 및 '직접 데이터베이스 코드 복사' 방식으로 노드의 최신 상태 유지를 보장합니다.
- '직접 복사'는 새로 가입한 노드에 대한 전체 데이터 복사를 수행하여 효율적인 동기화를 지원합니다.
레플리카 관리와 화이트보드 활용
섹션 개요: 레플리카 관리와 화이트보드의 역할에 대해 설명하며, 읽기 전용 데이터 처리 및 서버 간 통신 방식을 다룹니다.
레플리카 관리와 화이트보드 활용
- 레플리카는 읽기 용도로만 사용되며, 화이트보드를 통해 서버 간 정보 공유 및 관리됩니다.
클러스터 구성 변경
섹션 개요: 이 섹션에서는 Neo4j 서버의 클러스터를 설정하는 과정에 대해 설명합니다.
첫 번째 코어 인스턴스 설정
- 클러스터 내 멤버들을 구성합니다.
- HTTP 및 RAP 리슨 주소를 변경합니다.
- 파일 내 모든 변경 사항을 완료한 후, 해당 파일을 저장합니다.
두 번째 코어 인스턴스 실행
- 두 번째 코어 인스턴스를 실행하기 위해 첫 번째 코어를 복사하고 붙여넣기 합니다.
- 두 번째 코어의 구성 파일을 편집하고 변경 사항을 저장합니다.
Neo4j 서버 시작 및 클러스터 형성
- 모든 코어 인스턴스를 시작하기 위해 Neo4j 서버를 시작합니다.
- 최소 클러스터 형성 크기인 3개의 인스턴스가 필요하며, 다른 인스턴스도 시작해야 합니다.
클러스트 구성 확인 및 시작
섹션 개요: 이 섹션에서는 Neo4j 서버의 클러스트 구성과 시작 과정에 대해 다룹니다.
Core 멤버 발견 및 바인딩
- 초기 멤버 세트에서 다른 코어 멤버들을 발견하는 과정이 중요합니다.
- 각 코어 인스턴트가 다른 멤버들을 발견하고 있는지 확인할 수 있습니다.
데이터 전송과 읽기
- 각 인스턴트가 준비되면 브라우저를 통해 해당 서버에 연결하여 데이터 전송이 가능한지 확인할 수 있습니다.
Cluster Configuration Overview
이 섹션에서는 클러스터 구성에 대해 설명하고 있습니다.
리더로 데이터 쓰기 및 읽기
- 리더로 데이터를 쓸 수 있었으며, 리더에서 데이터를 읽을 수 있는지에 대한 질문이 제기됩니다.
- 데이터를 팔로워에 쓰려고 시도할 때, 메시지가 리더를 통과해야 한다는 명확한 안내가 제공됩니다.
클러스터 기능
- dbms.plustered 또는 개요 기능을 사용하여 클러스터의 모든 인스턴스 주소와 역할을 확인할 수 있습니다.
- 팔로워에서 데이터를 읽는 것은 허용되지만, 팔로워에 데이터를 쓰는 것은 허용되지 않습니다.
Replica Configuration Steps
복제본 구성 단골 및 설정 방법에 대해 다룹니다.
복제본 구성
- 복제본은 주로 데이터 읽기 용도로 사용되며, 핵심 인스턴스의 위치를 찾아야 합니다.
- 각각의 복제본 폴더에서 변경 사항을 가진 Neo4j 구성 파일을 수정해야 합니다.
Starting Replicas and Checking Data Replication
복제본 시작 및 데이터 복제 확인 방법을 다룹니다.
복제본 시작
- 여러 개의 복제본을 설정하는 방법과 각각의 변경 사항을 설명합니다.
- 명령 프롬프트에서 각각의 복제본 디렉토리 식별 후 시작하는 방법에 대해 안내합니다.
Testing Replica Functionality
복제본 기능 테스트 및 중단된 핵심 인스턴스 상황 시나리오에 대해 다룹니다.
테스트와 상황 시나리오
- 모든 복제본이 정상적으로 작동하는지 확인하기 위해 레플리카 중 하나에 로그인하여 데이터가 잘 복사되었는지 확인합니다.